



This chapter includes a short overview of the RDF data model and the Turtle notation, as well as some technologies like SPARQL, RDF Schema, and OWL that form part of the RDF ecosystem.
Readers that are already familiar with these technologies may skip this chapter and jump into the next chapter that describes the RDF validation problem.
The first draft of RDF was published in 1997 [68] and became a W3C recommendation in 1999 along with an XML syntax [69].
A class hierarchy which allows to describe a reasoning like if Socrates is human and all humans are mortals, then Socrates is mortal and property domains and ranges followed a year later. It is perhaps unfortunate that this came under the name RDF Schema (RDFS) as it didn’t offer any of the data constraints available in other schema languages like SQL’s DDL or W3C XML Schema.
In hindsight, this development path was clearly in tension with the priorities of everyday programmers and systems architects who care primarily about creating and accessing well-structured data, and perhaps secondarily about inference. Four years after RDFS, OWL extended the facilities provided by RDFS into an expressive ontology language that could describe the information required for instances of classes.
However, once again, the language was oriented toward a healthy, distributed information infrastructure and not that last mile which permits developers to confidently produce and consume data. While OWL could detect errors when one used a literal with the wrong datatype, or infer a subclass relationship between two classes explicitly declared disjoint, it simply would not complain if one says that every vehicle registration has an owner’s first name and last name, and then fails to supply those values. OWL is designed for an open world semantics, which means that it won’t conclude anything (e.g., signaling missing data) based on the absence of provided data. The absence of evidence is not evidence of absence.
Another four years later in 2008, the RDF community assembled to deliver a query language (SPARQL) to meet the most elementary of application needs, accessing data. The language met immediately with overwhelming acceptance and adoption. This ability to query led to the development of many new applications, as well as databases and libraries designed to facilitate application development. This energy led to the expansion of SPARQL 1.1 into update (analogous to SQL DDL) and HTTP protocol. It did not, however, elegantly solve the problem of RDF data description and verification.
When RDF was created in 1997, XML was quickly becoming a popular format. It had a strong influence on the RDF syntax which was called RDF/XML. That format is quite verbose and there appeared several proposals to have a more human-readable syntax for RDF.
In 2014, RDF 1.1 [25] was published as a revised version which maintained most of the data model and added support for other serialization formats like Turtle [78], Trig [18], or JSON-LD [5].
In this section we give a short overview of the RDF data model following the RDF 1.1 definitions and using Turtle as the serialization format.
The RDF data model is based on the concept of triples. Each triple consists of a subject, a predicate and an object. RDF triples are usually depicted as a directed arc connecting two nodes (subject and object) by an edge (predicate) (see Figure 2.2).

Figure 2.1: Example of RDF triple.
An RDF triple asserted means that some relationship, indicated by the predicate, holds between the resources denoted by the subject and object. This is known as an RDF statement. The predicate is an IRI that denotes a property. An RDF statement can be thought of as a binary relation identified by the property between the subject and object.
There can be three kinds of nodes: IRIs, literals, and blank nodes.
< and
>.
For example, an IRI can be
<http://example.org/john>.
Most RDF formats include some mechanism called prefix declaration which enables to simplify writing long IRIs declaring prefix labels.
A prefix label associates an alias with an IRI and enables the definition of prefixed names.
A prefixed name contains a prefix label and a local part separated by
: and
represents the IRI formed by concatenating the IRI associated with the prefix label and the local part.
For example, if
ex is declared as a prefix label to represent
<http://example.org/>,
then
ex:alice is a prefixed name that represents
<http://example.org/alice> (see Figure 2.2).
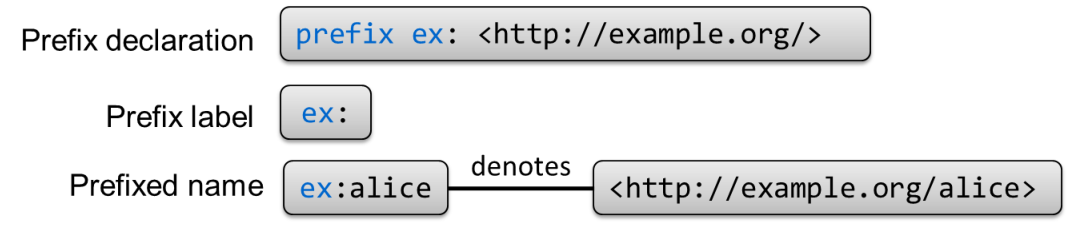
Figure 2.2: Example of prefix declaration.
There are some popular namespace aliases like
rdf,
xsd,
rdfs,
owl, etc.
The http://prefix.cc service can be used to lookup the IRI associated with those popular aliases.
The snippets of code used in this book assume these prefix declarations.
Table 1.1
"lexicalForm"^^datatype in Turtle.
For example:
"23"^^xsd:integer represents an integer with value
23 and
"1980-03-01"^^xsd:date represents the March 1, 1980.
All literals in RDF have an associated datatype.
In the case of string literals with no declared datatype, it is assumed the
xsd:string datatype by default.
So
"hi""hi"^^xsd:string.
A special type of literals are language-tagged strings, which are literals with datatype
rdf:langString that also contain a language tag [75] to identify a specific language.
Language-tagged strings are represented in Turtle as
"string"@tag.
For example:
"hola"@es represents the literal value
"hola"es).
_:id represents a blank node.
An RDF graph is a set of RDF triples. Notice that the edges of RDF graphs can only be IRIs. This is an important feature of RDF that enables to globally identify the predicates asserted by triples. The subjects can only be IRIs or blank nodes, while the objects can be IRIs, blank nodes or literals.
The following code represents an RDF graph in Turtle. The first three lines are prefix declarations and the rest represent a sequence of RDF triples separated by dots.
| prefix ex: <http://example.org/> prefix schema: <http://schema.org/> prefix dbr: <http://dbpedia.org/resource/> prefix xsd: <http://www.w3.org/2001/XMLSchema#> ex:alice schema:knows ex:bob . ex:bob schema:knows ex:carol . ex:bob schema:name "Robert" . ex:bob schema:birthDate "1980-03-10"^^xsd:date . ex:bob schema:birthPlace dbr:Oviedo . ex:carol schema:knows ex:alice . ex:carol schema:knows ex:bob . ex:carol schema:birthPlace dbr:Oviedo . |
The corresponding RDF graph has been depicted in Figure 2.2. Rounded boxes represent IRIs while orange rectangles represent literals.
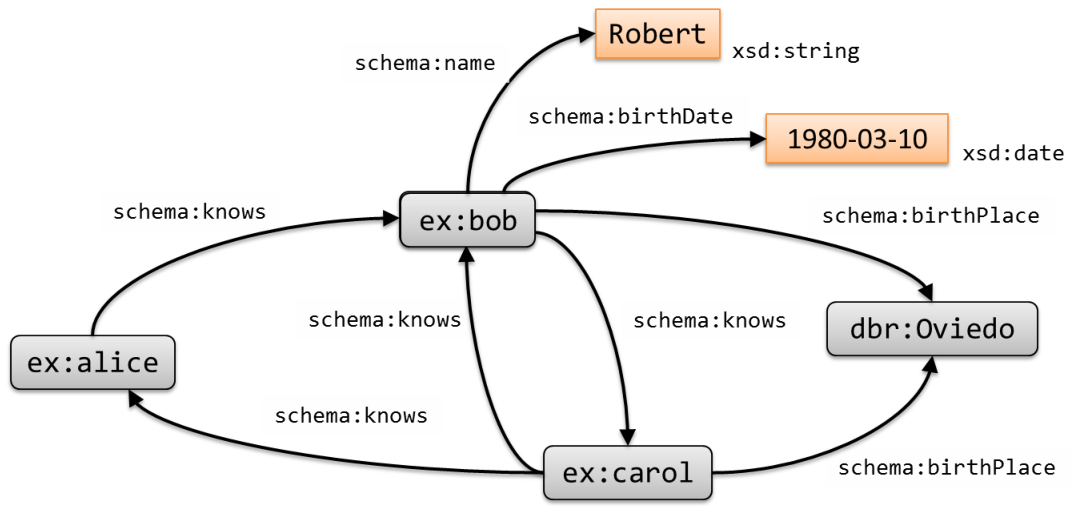
Figure 2.3: Example of an RDF graph.
Blank nodes can be used to make assertions about some elements whose IRIs are not known.
The following RDF Turtle code declares that
ex:alice knows someone
who knows
ex:dave,
and that
ex:carol knows someone who was born in the same place as
dave, whose age is 23. The graph is depicted in figure 2.
| prefix ex: <http://example.org/> prefix schema: <http://schema.org/> prefix dbr: <http://dbpedia.org/resource/> ex:alice schema:knows _:x . _:x schema:knows ex:dave . ex:carol schema:knows _:y . _:y schema:birthPlace _:z ; schema:age "23"^^xsd:integer . ex:dave schema:birthPlace _:z . |
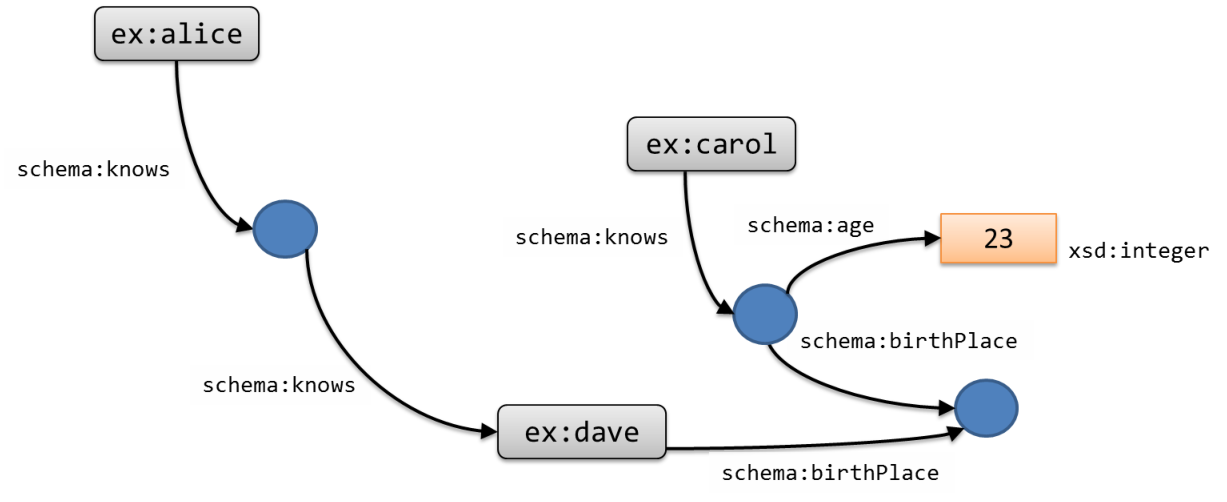
Figure 2.4: Example of an RDF graph with blank nodes.
An important feature of RDF graphs is that two independent RDF graphs can automatically be merged to obtain a larger RDF graph formed by the union on their sets of triples. Given the global nature of IRIs, nodes with the same IRI are automatically unified. Using shared IRIs makes the powerful statement the entities and relationships in one graph carry the same intent as they do in the other graphs using the same identifiers. In a sense, the use of RDF gets rid of the data merging problem and lets us focus on the hard problems of establishing shared entities and vocabularies.
For example, the union of the RDF graphs from Figures 2.2 and 2 is depicted in Figure 2.2. Turtle contains several simplifications to facilitate readability.
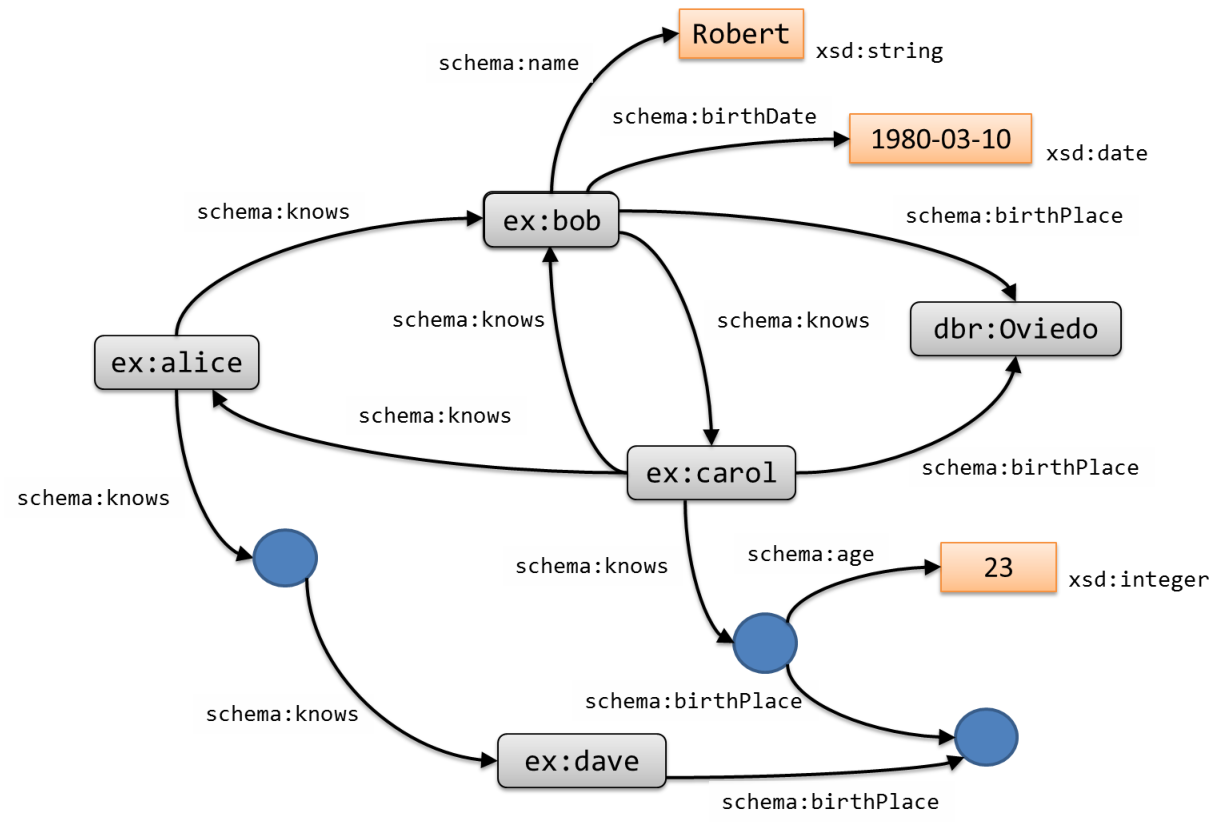
Figure 2.5: Merged RDF graph.
;). So, instead of writing | ex:bob schema:name "Robert" . ex:bob schema:birthDate "1980-03-10"^^xsd:date . ex:bob schema:birthPlace dbr:Oviedo . ex:bob schema:knows ex:carol . |
it is possible to write:
| ex:bob schema:name "Robert" ; schema:birthDate "1980-03-10"^^xsd:date ; schema:birthPlace dbr:Oviedo ; schema:knows ex:carol . |
,).Instead of writing
| ex:carol schema:knows ex:alice . ex:carol schema:knows ex:bob . |
it is possible to write:
| ex:carol schema:knows ex:alice, ex:bob . |
The RDF graph represented in Example 1 can be simplified as:
| prefix schema: <http://schema.org/> prefix ex: <http://example.org/> prefix dbr: <http://dbpedia.org/resource/> prefix xsd: <http://www.w3.org/2001/XMLSchema#> ex:alice schema:knows ex:bob . ex:bob schema:name "Robert" ; schema:birthDate "1980-03-10"^^xsd:date ; schema:birthPlace dbr:Oviedo ; schema:knows ex:carol . ex:carol schema:birthPlace dbr:Oviedo ; schema:knows ex:alice, ex:bob . |
Table 2.1: Shorthand syntax for numbers and Booleans in Turtle
Datatype Shorthand example Lexical example xsd:integer-3"-3"^^xsd:integerxsd:decimal-3.14"-3.14"^^xsd:decimalxsd:double3.14e2"3.14e2"^^xsd:doublexsd:booleantrue"true"^^xsd:boolean
X rdf:type Y asserts that
X has the type
represented by
Y.
In Turtle,
rdf:type can also be represented by the token
a, so the previous triple could also be represented as
X a Y.rdf:rest that end with
rdf:nil and whose values are declared by each value of the
rdf:first property. The following snippet declares the results of a marathon as an RDF Collection:
| :m23 schema:name "New York City Marathon" ; :results _:1 . _:1 rdf:first :dave . _:1 rdf:rest _:2 . _:2 rdf:first :alice . _:2 rdf:rest _:3 . _:3 rdf:first :bob . _:3 rdf:rest rdf:nil . |
Turtle has a special notation for RDF collections enumerating the values enclosed by round brackets. The previous example can also be represented in Turtle as:
| :m23 schema:name "New York City Marathon" ; :results (:dave :alice :bob) . |
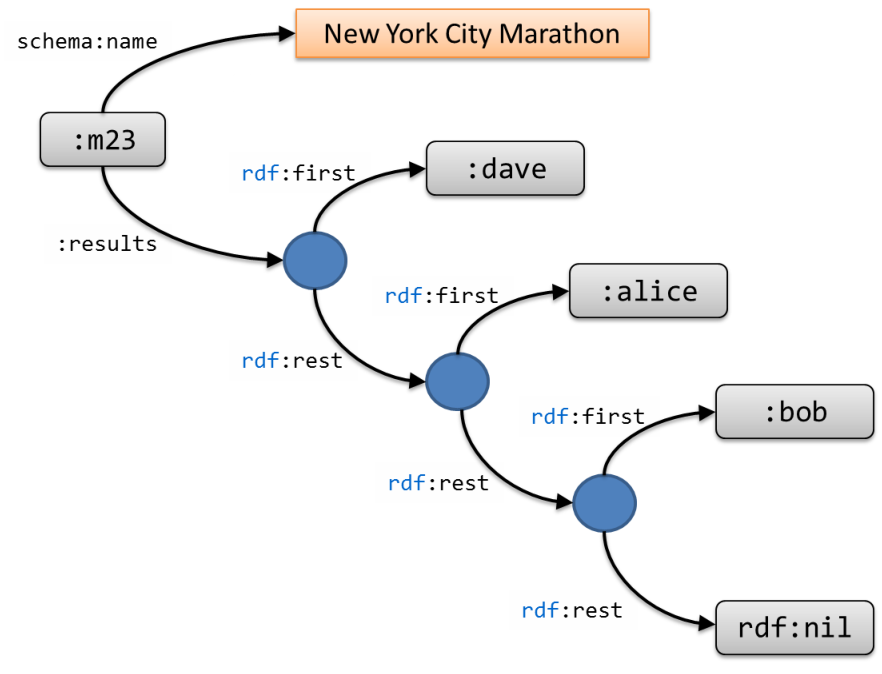
Figure 2.6: RDF collection example.
[ and
]).
In this way, Example 2 can be rewritten as follows.| ex:carol schema:knows [ schema:age 23 ; schema:birthPlace _:x ] . ex:dave schema:birthPlace _:x . ex:alice schema:knows [ schema:knows ex:dave ] . |
The RDF data model is very simple. This simplicity if part of its power as it enables RDF to be used as a data representation language in a lot of scenarios.
One of RDF strengths is to promote the use of IRIs instead of plain strings to facilitate merging data from heterogeneous sources and to avoid ambiguity. This poses the challenge of agreeing on common entities and relationships. Usually, those sets of entities and relationships are grouped in vocabularies which can be general-purpose or domain specific.
There are several well-known vocabularies like
schema.org which is a collaborative, community activity founded by Google, Microsoft, Yahoo, and Yandex that promotes the use of common structured data on the internet.
An interesting project is the LOV (Linked Open Vocabularies)1 project that collects open vocabularies and provides a vocabulary search engine.
Shared identifiers are frequently minted by some authority releasing data using those identifiers followed by community uptake of those identifiers.
Services like http://identifiers.org/ publish these identifiers and, in the frequent case where multiple identifiers exist for the same entity, map between them.
The property
owl:sameIndividualAs can be used to assert that mapping.
Consensus on vocabularies is typically by communities producing human-readable specifications, which is accompanied by some descriptions of the terms in the vocabulary using RDF Schema (see Section 2.4.2). Ontologies take this a step further by providing much more powerful inference and can be used to detect some errors in the conceptual model (for instance, if a vehicle registration conflated a car with its owner).
As we share more models, we implicitly raise our expectations for the accuracy of these models. George Box stated in 1976 that all models are wrong but some are useful [15]. Raising the bar for these models means we expect them to be useful in more situations than they were originally designed for.
Something as apparently simple as schema.org’s
schema:gender offers a simple model for a complex issue.
For at least 90% of the population, the model’s terms
schema:Male and
schema:Female suffice.
Extending that to 99% or 99.9% of the population we see these terms are insufficient for the many variations in both identity and biology.
Schema.org extends the model for these cases by permitting a string value.
FHIR HL7 (see Section 6.2) standards use a concept of administrative gender, which adds two other possibilities.
For simplicity in this chapter and the next, we will use a notion of
gender which is constrained to
male and
female.
In later chapters we will use this to show how RDF validation languages can use the extended value set to provide coverage for more use cases.
RDF was created as a language on which other technologies could be based on. The semantic web stack (also called layer cake) illustrates a hierarchy of technologies where RDF plays a central role. Although that stack is still evolving, there are two concepts that are worth mentioning: SPARQL and inference systems.
SPARQL (SPARQL Protocol and RDF Query Language) is an RDF query language which is able to retrieve and manipulate data stored in RDF. SPARQL 1.0 became a recommendation in 2008 [79] and SPARQL 1.1 was published in 2013 [44].
SPARQL is based on the notion of Basic Graph Patterns which are sets of triple patterns. A triple pattern is an extension of an RDF triple where some of the elements can be variables which are denoted by a question mark.
A Basic Graph Pattern matches a subgraph of the RDF data when RDF terms from that subgraph may be substituted for the variables and the result is an RDF graph equivalent to the subgraph.
The following SPARQL query retrieves the nodes
?x whose birth place is
dbr:Oviedo and the nodes
?y that are known by them.
| prefix : <http://example.org/> prefix schema: <http://schema.org/> prefix dbr: <http://dbpedia.org/resource/> SELECT ?x ?y WHERE { ?x schema:birthPlace dbr:Oviedo . ?x schema:knows ?y } |
Applying the previous SPARQL query to the RDF data defined in Example 2.2, a SPARQL processor would return the results shown in Table 2.2.
Table 2.2: Results of SPARQL query
?x?y:carol:alice:carol:bob:bob:carol
SPARQL queries consist of three parts [73].
The following SPARQL query returns people who know only one value.
| SELECT ?person ?known { ?person schema:knows ?known . { SELECT ?person (count(*) as ?countKnown) { ?person schema:knows ?known . } GROUP BY ?person } FILTER (?countKnown = 1) } |
It contains a nested query (lines 3–5) which groups each element with the number of known entries and a filter (line 8) which removes those elements whose counter is different to one.
A full introduction to SPARQL is out of the scope of this book. For the interested reader, we recommend [33].
SPARQL is a very expressive language which can be used to describe very complex queries. It can also be employed to validate the structure of complex RDF graphs [55]. In Section 23, we describe how SPARQL can be used to validate RDF.
RDF was designed so it could be used as a central piece for knowledge representation in the Web. The goal is that agents can automatically infer new knowledge in the form of new RDF statements from existing RDF graphs. To that end, several technologies were proposed to increase RDF expressiveness. In this section we will briefly review two of the most popular: RDF Schema and OWL.
RDF Schema was proposed as a data-modeling vocabulary for RDF data. The first public working draft of RDF Schema appeared in 1998 [16] and was accepted as a recommendation in 2004 [26].
It is a semantic extension of RDF which provides mechanisms to describe groups of resources and relationships between them. It defines a set of common classes and properties.
The main classes defined in RDFS are:
rdfs:Resource: the class of everything
rdfs:Class: the class of all classes
rdfs:Literal: the class of all literal values
rdfs:Datatype: the class of all datatypes
rdf:Property: the class of all properties
RDFS contains several properties like
rdfs:label,
rdfs:comment,
rdfs:domain,
rdfs:range,
rdf:type,
rdfs:subClassOf and
rdfs:subPropertyOf.
The following snippet contains some description about teachers and people using RDF Schema terms.
It declares that
schema:Person is an
rdfs:Class, as well as
:Teacher.
It also declares that the
:Teacher class is a subclass of
schema:Person which could be read as saying that every instance of
:Teacher is also an instance of
schema:Person.
Finally, it declares that
:teaches is a property that relates instances of
:Teacher with instances of
:Course, i.e.,
any two elements related by the property
:teaches will satisfy that the first is an
:Teacher and the second a
:Course.
| schema:Person a rdfs:Class . :Teacher a rdfs:Class ; rdfs:subClassOf schema:Person . :teaches a rdfs:Property ; rdfs:domain :Teacher ; rdfs:range :Course . |
RDF Schema processors contain several rules that enable them to infer new RDF data.
For example, for any
C rdfs:subClassOf D and
x a C they can infer
x a D,
and for any
p rdfs:domain C and
x p y they can infer
x a C.
If we apply those rules to the following data:
| :alice a :Person . :bob a :Teacher . :carol :teaches :algebra . |
An RDFS processor could infer that
:bob and
:carol have
rdf:type :Person and that
:algebra has
rdf:type :Course.
OWL (Web Ontology Language) defines a vocabulary for expressing ontologies based on description logics. It was published as a W3C recommendation in 2004 [29] and a new version, OWL 2, was accepted in 2009 [70]. OWL has several syntaxes: an RDF-based syntax, functional-style Syntax, manchester syntax, etc., and a formally defined meaning. We will use RDF syntax in the following examples with Turtle notation.
An ontology can be defined as a vocabulary of terms, usually about a specific domain and shared by a community of users. Ontologies specify the definitions of terms by describing their relationships with other terms in the ontology.
The main concepts in OWL are as follows.
owl:Thing that represents the set of all individuals and
owl:Nothing that represents the empty set.In the following example we declare two classes
:Man and
:Woman that have a property
:gender with the value
:Male or
:Female, respectively.
| :Man a owl:Class ; owl:equivalentClass [ owl:intersectionOf ( :Person [ a owl:Restriction ; owl:onProperty :gender ; owl:hasValue :Male ] ) ] . :Woman a owl:Class ; owl:equivalentClass [ owl:intersectionOf ( :Person [ a owl:Restriction ; owl:onProperty :gender ; owl:hasValue :Female ] ) ] . |
Now, we can define
:Person as the union of the
:Man and
:Woman classes,
and to declare that those classes are disjoint.
| :Person owl:equivalentClass [ rdf:type owl:Class ; owl:unionOf ( :Woman :Man ) ] . [ a owl:AllDisjointClasses ; owl:members ( :Woman :Man ) ] . |
Given the previous declarations, if we add the following instance data:
| :alice a :Woman ; :gender :Female . :bob a :Man . |
An OWL reasoner can infer the following triples:
| :alice a :Person . :bob a :Person . :bob :gender :Male . |
OWL can be used to define ontologies in several domains and there are several tools like the Protégé editor [66] which provide facilities for the creation and visualization of large ontologies.
As we mentioned in Section 1.1, one of the principles of linked data is to provide useful information when dereferencing a URI, using standards such as RDF. The goal is to return not only human-readable content like HTML that a machine can only represent in a browser, but also some machine understandable content in RDF which can be automatically processed.
There are two main possibilities: return different representations of the same resource using content negotiation, or return the same representation with RDF embedded.
The first approach can be easier to implement because developers have several mechanisms to transform a resource to different representations on the fly. A popular format nowadays is JSON-LD which is a JSON-based representation of RDF.
The Turtle Example 1 can be represented in JSON-LD as:
| {"@context": { "ex": "http://example.org/", "schema": "http://schema.org/", "dbr": "http://dbpedia.org/resource/", "xsd": "http://www.w3.org/2001/XMLSchema#", "name": { "@id": "schema:name" }, "birthDate": { "@id": "schema:birthDate", "@type": "xsd:date" }, "birthPlace": { "@id": "schema:birthPlace" }, "knows": { "@id": "schema:knows" } }, "@graph": [ { "@id": "ex:alice", "knows": {"@id": "ex:bob" } }, {"@id": "ex:bob", "name": "Robert", "knows": {"@id": "ex:carol"}, "birthDate": "1980-03-10", "birthPlace": {"@id": "dbr:Oviedo" } }, { "@id": "ex:carol", "knows": [{"@id": "ex:alice" }, {"@id": "ex:bob"}], "birthPlace": {"@id": "dbr:Oviedo" } } ] } |
An alternative approach is to embed RDF content in HTML.
RDFa can be used to embed RDF in HTML attributes.
| <div xmlns:schema="http://schema.org/" xmlns:ex="http://example.org/" xmlns:xsd="http://www.w3.org/2001/XMLSchema#" typeof="schema:Person" about="[ex:alice]"> My name is <span property="schema:name">Alice</span>. <p>I was born on <span property="schema:birthDate" content="1974-12-01" datatype="xsd:date">a Sunday, some time ago</span>, and I am a professor at the <span about="[ex:uniovi]" typeof="schema:Organization" property="schema:name" rel="schema:member" resource="[ex:alice]">University of Oviedo</span> </p> </div> |
An HTML browser visualizes the information:
My name is Alice. I was born on a Sunday, some time ago, and I am a professor at the University of Oviedo
while an RDFa processor obtains the following RDF data:
| ex:alice a schema:Person; schema:birthDate "1974-12-01"^^xsd:date; schema:name "Alice" . ex:uniovi a schema:Organization; schema:member ex:alice; schema:name "University of Oviedo" . |
Another alternative is to use microdata:
| <div itemscope itemtype="http://schema.org/Person" itemid="http://example.org/alice"> Home page of <span itemprop="name">Alice</span>. <p>I was born on <time itemprop="birthDate" datetime="1974-12-01">a Sunday, some time ago</time>, and I am a <span itemprop="jobTitle">Professor</span> at the <span itemscope itemprop="affiliation" itemtype="http://schema.org/Organization"> itemid="http://example.org/uniovi" <span itemprop="name">University of Oviedo</span> </span> </p> </div> |
Which represents the same information as the RDFa example.
Official online documents:
There are several books introducing the concepts of RDF and Semantic Web in general like:
And about particular topics: