



People have been using computers to record and reason about data for many decades. Typically, this reasoning is less esoteric than artificial intelligence tasks like classification.
A data modeler usually has some structure of the data that she is trying to model. That structure must be explicitly defined and communicated using some technology that can at the same time be understood by other people and also be processed by automatic systems that can check and enforce it. Using natural language for that is not enough as it can have ambiguities and is difficult to process by machines. On the other hand, enforcing that structure using some procedural programming language is difficult to maintain by other people. The right balance is usually to have some declarative language that can be readable by humans but at the same time parsed and checked by machines.
Rigorous data validation is like a contract that offers advantages to several different parties.
While RDF is a relative newcomer to the data scene, most widely-used structured data languages have a way to describe and enforce some form of data consistency. Examining UML, SQL, XML, JSON, and CSV allows us to set expectations for RDF validation.
The Unified Modeling Language (UML) is a general-purpose visual modeling language that can be used to provide a standard way to visualize the design of a system [85]. In 2005, the Object Management Group (OMG) published UML 2, a revision largely based on the same diagram notations, but using a modeling infrastructure specified using Meta-Object Facility (MOF). UML contains 14 types of diagrams, which are classified in three categories: structure, behavior and interaction. The most popular diagram is the UML class diagram, which defines the logical structure of a system in terms of classes and relationships between them. Given the Object Oriented tradition of UML, classes are usually defined in terms of sets of attributes and operations.
UML class diagrams are employed to visually represent data models.
Figure 11 represents an example of a UML class diagram.
In this case, there are two classes,
User and
Course with several attributes and two relationships.
The relation
enrolledIn establishes that a user can be enrolled in a course.
The cardinalities
0..* means that a user may be enrolled in several courses while a cardinality
1..* means that a course must have at least one user enrolled.
The other relationship is
instructor which means that a course must have one instructor (cardinality
1) while a user can be the instructor of 0 or several courses.
There is another relationship (
knows) between users.
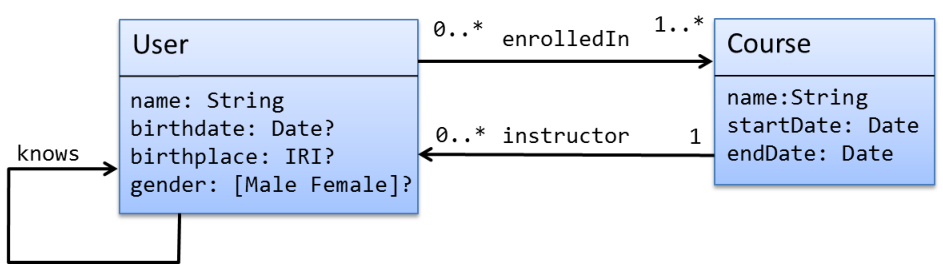
Figure 3.1: Example of UML class diagram.
UML diagrams are typically not refined enough to provide all the relevant aspects of a specification. There is, among other things, a need to describe additional constraints about the objects in the model. OCL (Object Constraint Language)1 has been proposed as a declarative language to define this kind of constraints. It can also be used to define well-formedness rules, pre- and post-conditions, model transformations, etc.
OCL contains a repertoire of primitive types (Integer, Real, Boolean, String) and several constructs to define compound datatypes like tuples, ordered sets, sequences, bag and sets.
The following code represents some constraints in OCL:
that the gender must be
'Male''Female'< to compare dates while in OCL dates are not primitive types.
,
| course User inv: self.gender->forAll(g | Set{'Male','Female'}->includes(g) ) self.knows->forAll(k | k <> self) context Course inv: self.startDate < self.endDate |
Probably the largest deployment of machine-actionable data is in relational databases, and certainly the most popular access to relational data is by Structured Query Language (SQL). One challenge in describing SQL is the difference between the ISO standard and deployed implementations.
SQL is designed to capture tabular data, with some implementations enforcing referential integrity constraints for consistent linking between tables. SQL’s Data Definition Language (DDL) is used to lay out a table structure; SQL is used to populate and query those tables. The SQL implementations that do enforce integrity constraints do so when data is inserted into tables.
The concept of DDL was introduced in the Codasyl database model to write the schema of a database describing the records, fields and sets of the user data model. It was later used to refer to a subset of SQL for creating tables and constraints. DDL statements list the properties in a particular table, their associated primitive datatypes, and list uniqueness and referential constraints.
| CREATE TABLE User ( id INTEGER PRIMARY KEY NOT NULL, name VARCHAR(40) NOT NULL, birthDate DATE, birthPlace VARCHAR(50), gender ENUM('male','female') ); CREATE TABLE Course ( id INTEGER PRIMARY KEY, StartDate DATE not null, EndDate DATE not null, Instructor INTEGER FOREIGN KEY REFERENCES User(id) ) CREATE TABLE EnrolledIn ( studendId INTEGER FOREIGN KEY REFERENCES User(id), courseId INTEGER FOREIGN KEY REFERENCES Course(id), ) |
While implementation support for constraints and datatypes varies, popular datatypes include numerics like various precisions of integer or float, characters, dates and strings.
Two popular constraints in DDL are for primary and foreign keys. In SQL and DDL, attribute values are primitive types, which is to say that a user’s course is not a course record, but instead typically an integer that is unique in some table of courses.

Figure 3.2: Example of two tables.
Because RDF is a graph, one would typically bypass this reference convention and create a graph where a user’s course is a course instead of a reference.
XML was proposed by the W3C as an extensible markup language for the Web around 1996 [98]. XML derives from SGML [42], a meta-language that provides a common syntax for textual markup systems and from which the first versions of HTML were also derived. Given its origins in typesetting, the XML model is adapted to represent textual information that contains mixed text and markup elements.
The XML model is known as the XML Information Set (XML InfoSet) and consists of a tree structure, where each node of the tree is defined to be an information item of a particular type. Each item has a set of type-specific properties associated with it. At the root there is a document item, which has exactly one element as its child. An element has a set of attribute items and a list of child elements or text nodes. Attribute items may contain character items or they may contain typed data such as name tokens, identifiers and references. Element identifiers and references may be used to connect nodes transforming the underlying tree into a graph.
An example of a course representation in XML can be:
| <course name="Algebra"> <student id="alice"> <name>Alice</name> <gender>Female</gender> <comments>Friend of <person ref="bob">Robert</person></comments> </student> <student id="bob"> <name>Robert</name> <gender>Male</gender> <birthDate>1981-09-24</birthDate> </student> </course> |
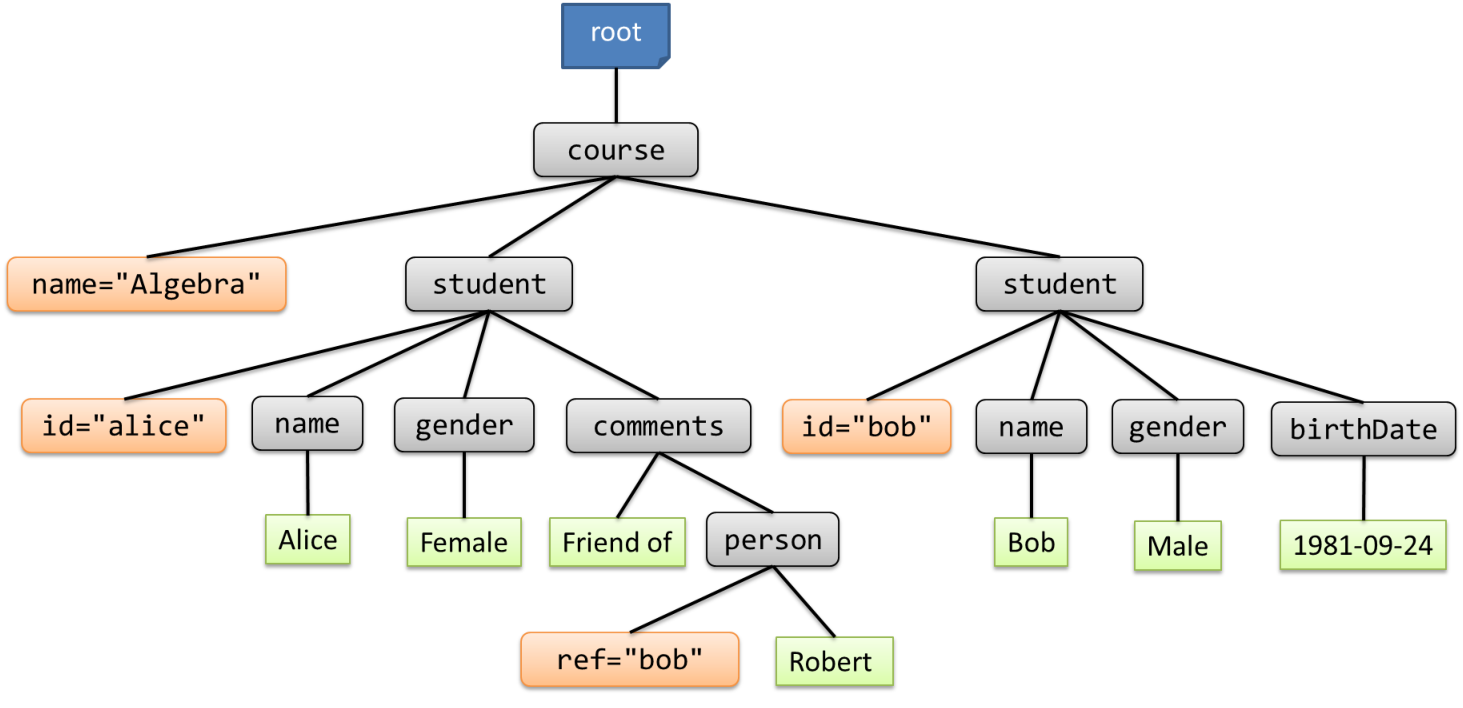
Figure 3.3: Tree structure of an XML document.
XML became very popular in industry and a lot of technologies were developed to query and transform XML. Among them, XPath was a simple language to select parts of XML documents that was embedded in other technologies like XSLT or XQuery.
The next XPath snippet finds the names of all students whose gender is
"Female"
| //student[gender = "Female"]/name |
XML defines the notion of well-formed documents and valid documents. Well-formed documents are XML documents with a correct syntax while valid documents are documents that in addition of being well-formed, conform to some schema definition.
If one decides to define a schema, there are several possibilities.
A DTD to validate the XML file in Example 14 could be:
| <!ELEMENT course (student*)> <!ELEMENT student (name,gender,birthDate?)> <!ELEMENT name (#PCDATA)> <!ELEMENT gender (#PCDATA)> <!ELEMENT birthDate (#PCDATA)> <!ATTLIST student id ID #REQUIRED> <!ATTLIST course name CDATA #IMPLIED> |
DTD defines the structure of XML using a basic form of regular expressions. However, DTDs have a limited support for datatypes. For example, it is not possible to validate that the birth date of a student has the shape of a date.
| <xs:schema xmlns:xs='http://www.w3.org/2001/XMLSchema'> <xs:element name="course"> <xs:complexType> <xs:sequence> <xs:element name="student" minOccurs='1' maxOccurs='100' type="Student"/> </xs:sequence> <xs:attribute name="name" type="xs:string" /> </xs:complexType> </xs:element> <xs:complexType name="Student"> <xs:sequence> <xs:element name="name" type="xs:string" /> <xs:element name="gender" type="Gender" /> <xs:element name="birthDate" type="xs:date" minOccurs='0'/> </xs:sequence> <xs:attribute name="id" type="xs:ID" use='required'/> </xs:complexType> <xs:simpleType name="Gender"> <xs:restriction base="xs:token"> <xs:enumeration value="Male"/> <xs:enumeration value="Female"/> </xs:restriction> </xs:simpleType> </xs:schema> |
An XML Schema validator decorates each structure of the XML document with additional information called the Post-Schema Validation Infoset, or PSVI. This structure contains information about the validation process that can be later employed by other XML tools.
The following code contains a RelaxNG schema to validate Example 14 using the RelaxNG compact syntax.
| element course { element student { element name { xsd:string }, element gender { "Male" | "Female" }, element birthDate { xsd:date }?, attribute id { xsd:ID } }* , attribute name { xsd:string } } |
The same example can be expressed in XML as:
| <element name="course" xmlns="http://relaxng.org/ns/structure/1.0" datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes"> <zeroOrMore> <element name="student"> <element name="name"> <data type="string"/> </element> <element name="gender"> <choice> <value>Female</value> <value>Male</value> </choice> </element> <optional> <element name="birthDate"> <data type="date"/> </element> </optional> <attribute name="id"> <data type="ID"/> </attribute> </element> </zeroOrMore> <attribute name="name"> <data type="string"/> </attribute> </element> |
Schematron has more expressive power than other schema languages like DTDs, RelaxNG or XML Schema as it can express complex constraints that are impossible with them. In fact, it is often used to define business rules.
Although Schematron can be used as a stand-alone, it is commonly used in cooperation with other schema languages which define the document structure.
If we have XML documents containing course grades like the following:
| <course name="Algebra"> <student id="S234"> <name>Alice</name> <grade>8</grade> </student> <student id="B476"> <name>Robert</name> <grade>5</grade> </student> <average>9</average> </course> |
We can define the following Schematron file to validate.
S (lines 4–8).<average> is the mean of the grades. | <sch:schema xmlns:sch="http://purl.oclc.org/dsdl/schematron"> <sch:pattern name="Check Ids"> <sch:rule context="student"> <sch:assert test="starts-with(@id,'S')" >IDs must start by S</sch:assert> </sch:rule> </sch:pattern> <sch:pattern name="Check mean"> <sch:rule context="average"> <sch:assert test="sum(//student/grade) div count(//student/grade) = ." >Value of <sch:name/> does not match mean </sch:assert> </sch:rule> </sch:pattern> </sch:schema> |
Schematron is more expressive than other schema languages like DTDs, XML Schema, or RelaxNG as it can define business rules and co-occurrence constraints at the same time that it can also define structural constraints like the other ones. Nevertheless, Schematron rules can become complex to define and debug. A popular approach is to combine both approaches, defining the XML document structure with a traditional schema language and complementing it with schematron rules.
Different approaches have been proposed to indicate how an XML document has to be validated against a schema. Some of those approaches are the following.
| <!DOCTYPE course [ <!ELEMENT course (student*) > <!ELEMENT student (name,grade)> <!ATTLIST student id CDATA #REQUIRED> ]> <course name="Algebra"> ... </course> |
xsi:schemaLocation or
xsi:noNamespaceSchemaLocation attributes. For example, the following XML document directly declares that it follows the schema identified by
http://example.org/ns/Course which is located at
http://example.org/course.xsd:
| <course xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://example.org/ns/Course http://example.org/course.xsd"> ... </course> |
<?xml-model ?> has been proposed to associate an XML document with a schema [43]. | <?xml-model href="http://example.org/course.rng" ?> <?xml-model href="http://example.org/course.xsd" ?> <course name="Algebra"> ... </course> |
Note that the XML model processing instruction enables to use multiple schemas for the same document.
As can be seen XML provides several ways to associate XML data with schemas for their validation.
JSON was proposed by Douglas Crockford around 2001 as a subset of Javascript (the original acronym was Javascript Object Notation). It has evolved as an independent data-interchange format with its own ECMA specification [35].
A JSON value, or JSON document, can be defined recursively as follows.
true,
false and null are JSON values."Note that in the case of arrays and objects the values vi can again be objects or arrays, thus allowing the documents an arbitrary level of nesting. In this way, the JSON data model can be represented as a tree [14].
The following example contains a JSON object with two keys:
name and
students.
The value of
name is a string while the value of
students is an array of two objects.
| { "name": "Algebra" , "students": [ { "name": "Alice", "gender": "Female", "age": 18 }, { "name": "Robert", "gender": "Male", "birthDate": "1981-09-24" } ] } |
Figure 19 shows a tree representation of the previous JSON value.
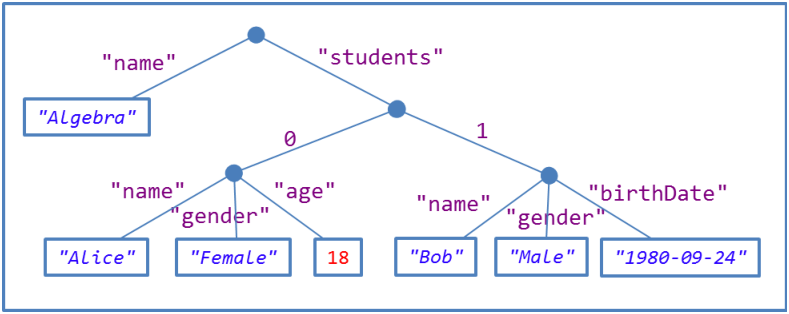
Figure 3.4: Tree structure of JSON.
JSON Schema [101] was proposed as an Schema language for JSON with a role similar to XML Schema for XML. It is written itself using JSON syntax and is programming language agnostic. It contains the following predefined datatypes: null, Boolean, object, array, number and string, and allows to define constraints on each of them.
In JSON Schema, it is possible to have reusable definitions which can later be referenced. Recursion is not allowed between references [74].
The following example contains a JSON schema that can be used to validate Example 19.
It declares
student as an object type with four properties:
name,
gender,
birthDate and
age.
The first two are required and some constraints can be added on their values.
The JSON value has type
object and contains two properties:
name, which must be a string value,
and
students which must be an array, whose items conform to the
student definition.
| { "$schema": "http://json-schema.org/draft-04/schema#", "definitions": { "student": { "type": "object", "properties": { "name": {"type": "string" }, "gender": {"type": "string", "enum":["Male","Female"]}, "birthDate": {"type": "string", "format": "date" }, "age": {"type": "integer","minimum": 1 } }, "required": ["name","gender"] } }, "type": "object", "properties": { "name": { "type": "string" }, "students" : { "type": "array", "items": { "$ref": "#/definitions/student" } } }, "required": ["name","students"] } |
Comma-Separated Values (CSV) and Tab-Separated Values (TSV) files have historically had no format-specific schema language. A common use case for CSV (and TSV) is to import it into a relational database, where it is subject to the same integrity constraints as any other SQL data. However, wide-ranging practices for documenting table structure and semantics have historically made it hard for consumers of CSV to consume published CSV data with confidence. Column headings and meanings may appear as rows in the CSV file, columns in an auxiliary CSV or flat file, or be omitted entirely.
Spreadsheets are another common generator and consumer of CSV data. Some spreadsheets may have hand-tooled integrity constraints but they offer no standard schema language.
While traditionally schema-less, a recent standard, CSV on the Web (CSVW) attempts to describe the majority of deployed CSV data. This includes semantics (e.g., mapping to an ontology), provenance, XML Schema length and numeric value facets (e.g., minimum length, max exclusive value), and format and structural constraints like foreign keys and datatypes.
CSVW describes a wide corpus of existing practice for publishing CSV documents. Because of it’s World Wide Web orientation, it includes internationalization and localization features not found in other schema languages. Where most data languages standardize the lexical representation of datatypes like dateTime or integer, CSVW describes a wide range of region or domain-specific datatypes. For instance, the following can all be representations of the same numeric value: 12345.67, 12,345.67, 12.345,67, 1,23,45.67.
CSVW is also unusual in that it can be used to describe denormalized data. Because of this, it includes separator specifiers to aid in micro-parsing individual data cells into sequences of atomic datatypes.
CSVW is a very new specification and applies to a domain with historically no standard schema language. Tools like CSVLint2 are adopting CSVW as a way to offer interoperable schema declarations to enable data quality tests.
As we can see in Table 3.1, most data technologies have some description and validation technology which enables users to describe the desired schema of the data and to check if some existing data conforms with that schema.
Table 3.1: Data validation approaches
Data format Validation technology Relational databases DDL XML DTD, XML Schema, RelaxNG, Schematron CSV CSV on the Web JSON JSON Schema RDF ShEx/SHACL
Although there have been several previous attempts to define RDF validation technologies (see Section 3.3) this book focuses on ShEx and SHACL.
In this section we describe what are the particular concepts of RDF that have to be taken into account for its validation:
RDF is composed of triples, which have arcs (predicates) between nodes. We can describe:
Figure 3.2 presents an RDF node and its corresponding Shape.
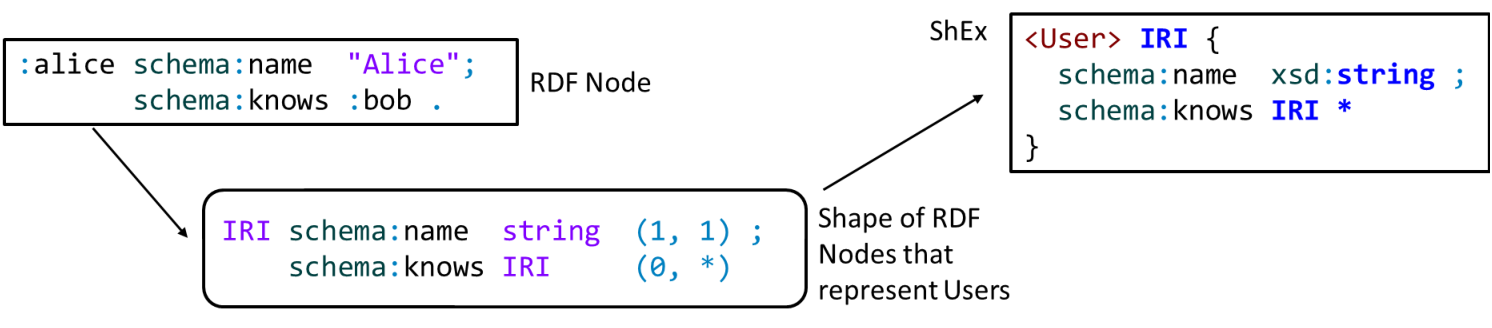
Figure 3.5: RDF node and its shape.
A difference between RDF and XML with regards to their data model is that while in RDF, the arcs are unordered, in XML, the sub-elements form an ordered sequence. RDF validation languages must not assume any order on how the arcs of a node will be treated, while in XML, the order of the elements affect the validation process.
From a theoretical point of view, the arcs related with a node in RDF can be represented as a bag or multiset, i.e., a set which allows duplicate elements.
Notice that RDF validation is different from ontology definition and also different from instance data.
Figure 3.2 represents the difference between instance data, ontology definitions, and RDF validation.

Figure 3.6: RDF validation vs. ontology definition.
Given the open and flexible nature of RDF, nodes in RDF graphs can have zero, one or many
rdf:type arcs.
Some application can use nodes of type
schema:Person with some properties while another application can use nodes with the same type but different properties.
For example,
schema:Person can represent friend, invitee, patient,...in different applications or even in different contexts of the same application.
The same types can have different meanings and different structure depending on the context.
While from an ontology point of view a concept has a single meaning, applications that are using that same concept may select different properties and values and thus, the corresponding representations may differ.
Nodes in RDF graphs are not necessarily annotated with fully discriminating types.
This implies that it is not possible to validate the shape of a node by just looking at its
rdf:type arc.
We should be able to define specific validation constraints in different contexts.
Validation can be performed before or after inference. Validation after inference (or validation on a backward-chaining store that does inference on the fly) checks the correctness of the implications. An inference testing service could use an input schema describing the contents of the input RDF graph and an output schema describing the contents of the expected inferred RDF graph. The service can check that instance data conforms to the input schema before inference and that after applying a reasoner, the resulting RDF graph with inferred triples, conforms to the output schema.
PersonShape requires an
rdf:type of
:Person
TeacherShape requires an
rdf:type of
:Teacher
If we validate the following RDF graph without inference, only
:alice would match
PersonShape.
However, if we validate the RDF graph that results of applying RDF Schema inference, then both
:bob and
:carol would also match
PersonShape.
| :teaches rdfs:domain :Teacher . :Teacher rdfs:subClassOf :Person . :alice a :Person . :bob a :Teacher . :carol :teaches :algebra . |
Validation workflows will likely perform validation both before and after validation. Systems which perform possibly incomplete inference can use this to verify that their light-weight, partial inference is producing the required triples.
RDF was born as a schema-less language, a feature which provided a series of advantages in terms of flexibility and adaptation of RDF data to different scenarios.
The same property, can have different types of values.
For example, a property like
schema:creator can have as value a string literal or a more complex resource.
| :angie schema:creator "Keith Richards" , [ a schema:Person ; schema:givenName "Mick" ; schema:familyName "Jagger" ] . |
Sometimes, the same property is used for different purposes in the same data. For example, a book can have two codes with different structure.
| :book schema:name "Moby Dick"; schema:productID "ISBN-10:1503280780"; schema:productID "ISBN-13:978-1503280786" . |
This is a natural consequence of the re-use of general properties,3 which is especially common in domains where many kinds of data are represented in the same structure.
Repeated properties which require different model for each value appear frequently in real-life scenarios. For example, FHIR (see Section 6.2 for a more detailed description) represents clinical records using a generic observation object. This means that a blood pressure measurement is recorded using the same data structure as a temperature. The challenge is that while a temperature observation has one value:4
| :Obs1 a fhir:Observation ; fhir:Observation.code fhir:LOINC8310-5 ; fhir:Observation.valueQuantity 36.5 ; fhir:Observation.valueUnit "Cel" . |
a blood pressure observation has two:5
| :Obs2 a fhir:Observation ; fhir:Observation.code fhir:LOINC55284-4 ; fhir:Observation.component [ fhir:Observation.component.code fhir:LOINC8480-6 ; fhir:Observation.component.valueQuantity 107 ; fhir:Observation.component.valueUnit "mm[Hg]" ]; fhir:Observation.component [ fhir:Observation.component.code fhir:LOINC8462-4 ; fhir:Observation.component.valueQuantity 60 ; fhir:Observation.component.valueUnit "mm[Hg]" ] . |
We can see that a blood pressure observation must have two instances of the
fhir:Observation.component property,
one with a code for a systolic measurement and the other with a code for a diastolic measurement.
Treating these two constraints on the property
fhir:Observation.component individually would cause the systolic constraint to reject the diastolic measurement and the diastolic constraint to reject the systolic measurement—both constraints must be considered as being satisfied if one of the components satisfies one and the other component satisfies the other.
The RDF dictum of anyone can say anything about anything is in tension with conventional data practices
which reject data with any assertions that are not recognized by the schema.
For SQL schemas, this is enforced by the data storage itself; there’s simply no place to record assertions that does not correspond to some attribute in a table specified by the DDL.
XML Schema offers some flexibility with constructs like
<xs:any processContents="skip">
but these are rare in formats for the exchange of machine-processable data.
Typically the edict is if you pass me something I do not understand fully, I will reject it.
For shapes-based schema languages, a shape is a collection of constraints to be applied to some node in an RDF graph and if it is
closed, every property attached to that node must be included in the shape.
Even if the receiver of the data permits extra triples, it may not be able to store or return them. For instance, a Linked Data container may accept arbitrary data, search for sub-graph which it recognizes, and ignore the rest. A user expecting to put data in such a container and retrieve it will have a rude surprise when he gets back only a subset of the submitted data. Even if the receiver does not validate with closed shapes, the user may wish to pre-emptively validate their data against the receiver’s schema, flagging any triples not recognized by the schema.
Another value of closed shapes is that it can be used to detect spelling mistakes.
If a shape in a schema includes an optional
rdfs:label and a user has accidentally included an
rdf:label, the schema has no way to detect that mistake unless all unknown properties are reported.
Like with repeated properties, the validation of closed shapes must consider property constraints as a whole, rather than examining each individually.
In this section we review some previous approaches that have already been proposed to validate RDF.
Query-based approaches use a query Language to express validation constraints. One of the earliest attempts in this category was Schemarama [63], by Libby Miller and Dan Brickley, which applied Schematron to RDF using the Squish query language. That approach was later adapted to use TreeHuger which reinterpreted XPath syntax to describe paths in the RDF model [95].
Once SPARQL appeared in scene, it was also adopted for RDF validation. SPARQL has a lot of expressiveness and can be used to validate numerical and statistical computations [55].
If we want to validate that an RDF node has a
schema:name property with a
xsd:string value and a
schema:gender property whose value must be one of
schema:Male or
schema:Female in SPARQL,
we can do the following query:
| ASK { { SELECT ?Person { ?Person schema:name ?o . } GROUP BY ?Person HAVING (COUNT(*)=1) } { SELECT ?Person { ?Person schema:name ?o . FILTER ( isLiteral(?o) && datatype(?o) = xsd:string ) } GROUP BY ?Person HAVING (COUNT(*)=1) } { SELECT ?Person (COUNT(*) AS ?c1) { ?Person schema:gender ?o . } GROUP BY ?Person HAVING (COUNT(*)=1) } { SELECT ?Person (COUNT(*) AS ?c2) { ?Person schema:gender ?o . FILTER ((?o = schema:Female || ?o = schema:Male)) } GROUP BY ?Person HAVING (COUNT(*)=1) } FILTER (?c1 = ?c2) } |
Using plain-SPARQL queries for RDF validation has the following benefits.
But it also has the following problems.
SPARQL Inferencing Notation (SPIN)[51] was introduced by TopQuadrant as a mechanism
to attach SPARQL-based constraints and rules to classes.
SPIN also contained templates, user-defined functions and template libraries.
SPIN rules are expressed as SPARQL ASK queries where
true indicates an error or
CONSTRUCT queries that produce violations.
SPIN uses the expressiveness of SPARQL plus the semantics of
the variable
?this standing for the current focus node (the subject being validated).
SPIN has heavily influenced the design of SHACL. The Working Group has decided to offer a SPARQL based semantics and the second part of the working draft also contains a SPIN-like mechanism for defining SPARQL native constraints, templates and user-defined functions. There are some differences like the renaming of some terms and the addition of more core constraints like disjunction, negation or closed shapes. The following document describes how SHACL and SPIN relate (http://spinrdf.org/spin-shacl.html).
There have been other proposals using SPARQL combined with other technologies. Fürber and Hepp [39] proposed a combination between SPARQL and SPIN as a semantic data quality framework, Simister and Brickley [90] propose a combination between SPARQL queries and property paths which is used by Google and Kontokostas et al. [53] proposed RDFUnit a Test-driven framework which employs SPARQL query templates that are instantiated into concrete quality test queries.
Inference based approaches adapt RDF Schema or OWL to express validation semantics. The use of Open World and Non-unique name assumption limits the validation possibilities. In fact, what triggers constraint violations in closed world systems leads to new inferences in standard OWL systems. Motik, Horrocks, and Sattler [64] proposed the notion of extended description logics knowledge bases, in which a certain subset of axioms were designated as constraints.
In [72], Peter F. Pater-Schneider, separates the validation problem in two parts: integrity constraint and closed-world recognition. He shows that description logics can be implemented for both by translation to SPARQL queries.
In 2010, Tao et al. [96] had already proposed the use of OWL expressions with Closed World Assumption and a weak variant of Unique Name Assumption to express integrity constraints.
Their work forms the bases of Stardog ICV [21] (Integrity Constraint Validation), which is part of the Stardog database. It allows to write constraints using OWL syntax but with a different semantics based on a closed world and unique name assumption. The constraints are translated to SPARQL queries. As an example, a User could be specified as follows.
The following code declares several integrity constraints in Stardog ICV.
It declares that nodes that are instances of
schema:Person must have at exactly one value of
schema:name (it is a functional property) which must be a
xsd:string,
an optional value of
schema:gender which must be either
schema:Male or
schema:Female,
and zero or more values of
schema:knows which must be instances of
schema:Person.
| schema:Person a owl:Class ; rdfs:subClassOf [ owl:onProperty schema:name ; owl:minCardinality 1 ] , [ owl:onProperty schema:gender; owl:minCardinality 0 ] [ owl:onProperty schema:knows ; owl:minCardinality 0 ] . schema:name a owl:DatatypeProperty , owl:FunctionalProperty; rdfs:domain schema:Person ; rdfs:range xsd:string . schema:gender a owl:ObjectProperty , owl:FunctionalProperty; rdfs:domain schema:Person ; rdfs:range :Gender . schema:knows a owl:ObjectProperty ; rdfs:domain schema:Person ; rdfs:range schema:Person . schema:Female a :Gender . schema:Male a :Gender . |
Instance nodes are required to have an
rdf:type declaration whose value is
schema:Person.
While SPARQL and OWL Closed World were existing languages which were applied to RDF validation, some novel languages have been designed specifically to that task.
OSLC Resource Shapes [86] have been proposed as a high level and declarative description of the expected contents of an RDF graph expressing constraints on RDF terms.
Example 23 can be represented in OSLC as:
| :user a rs:ResourceShape ; rs:property [ rs:name "name" ; rs:propertyDefinition schema:name ; rs:valueType xsd:string ; rs:occurs rs:Exactly-one ; ] ; rs:property [ rs:name "gender" ; rs:propertyDefinition schema:gender ; rs:allowedValue schema:Male, schema:Female ; rs:occurs rs:Zero-or-one ; ]. |
Dublin Core Application Profiles [23] also define a set of validation constraints using Description Templates
Fischer et al. [38] proposed RDF Data Descriptions as another domain specific language that is
compiled to SPARQL.
The validation is class based in the sense that RDF nodes are validated against a class
C
whenever they contain an
rdf:type C declaration.
This restriction enables the authors to handle the validation of large datasets and to define some optimization techniques which could be applied to shape implementations.
In this section we collect the different validation requirements that we have identified for an RDF validation language.
Some of this requirements have been borrowed from the SHACL Use Cases and Requirements document [91]. Other collections of validation requirements have also been proposed [13].
Given that the RDF data model is a graph model. An RDF validation language must be able to describe graph structures. The following set of requirements could be applied to any validation language related with graphs.
rdfs:subClassOf property can be expressed as
rdfs:subClassOf*.The schema language must be able to check the different types of contents that appear in the RDF data model.
xsd:integer between 10 and 20.
rdf:langString.This set of requirements are common to technologies that model data.
The following requirements refer to the relationship between schema and instance data, and to the mechanism by which the validation process is triggered.
The following set of requirements refer to the usability of the schema language.
In this chapter we learned which are the main motivations for validating RDF. We started describing what do other technologies do for validation with an overview of UML, SQL, XML, JSON, and so on. This section was aimed to present those technologies and to gather some list of validation requirements that are common to all of them.
We also described some of the previous RDF validation approaches and collected a list of validation requirements that a good schema language for RDF validation must fulfil. Notice that some of them contradict each other, so it is necessary to reach some compromise solution.
Non-RDF schema languages
RDF validation approaches
has topping property rather than a
has pizza topping property.