



In this chapter we describe several applications of RDF validation. We start with the WebIndex, a medium-size linked data portal that was one of the earliest applications of ShEx. We describe it using ShEx and SHACL so the reader can see how both formalisms can be applied to describe RDF data.
In Section 6.2, we present the use of ShEx in HL7 FHIR, which was one of the main motivations for the development of ShEx.
Section 6.3 describes Springer Nature SciGraph, a real-world application of SHACL. Section 6.4 talks about validation use cases that have emerged in the DBpedia project.
We end the chapter with two exercises: the validation of ShEx files, encoded as RDF using ShEx itself (Section 6.5), and the validation of SHACL shapes graphs in RDF using SHACL (Section 6.6). These exercises help us understand the expressiveness of both formalisms.
Linked data portals have emerged as a way to publish data on the Web in accordance with principles that improve data reuse and integration. As discussed in Section 1.1, linked data uses RDF to make statements that establish relationships between arbitrary things. In this section, we consider one of the earliest practical applications of ShEx, the description of a real linked data portal, the WebIndex, and its data model. Some contents of this section have been taken from this paper [58] where we also compare the performance of two early implementations of ShEx and SHACL.
The WebIndex is a multi-dimensional measure of the World Wide Web’s contribution to development and human rights globally. In its latest edition (from 2014), it covers 81 countries and incorporates indicators that assess several areas such as universal access; freedom and openness; relevant content; and empowerment. Its first version provided a data portal where the data was obtained by transforming raw observations and precomputed values from Excel sheets into RDF. The second version added an approach to validation and computation that resulted in a verifiable version of the index data.
The WebIndex data model is based on the RDF Data Cube vocabulary [24] and reuses several vocabularies such as Organization ontology [83] and Dublin Core [10].
Figure 6.1 shows the main concepts of the data model. The boxes represent the different shapes of nodes that are published in the data portal.
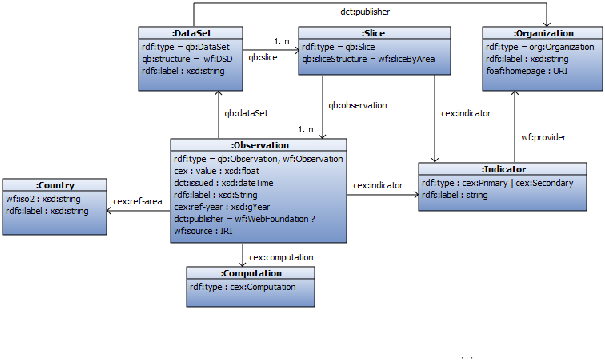
Figure 6.1: Simplified WebIndex data model.
The main concept is an observation of type
wf:Observation which has a float value
cex:value for a given indicator, as well as the country, year, and dataset.
Observations can be raw observations, which are obtained from an external source, or computed observations,
which are obtained from other observations by computational processes.
A dataset contains a number of slices, each of which also contains a number of observations.
Indicators are provided by an organization of type
org:Organization, which is based on the Organization ontology.
Datasets are also published by organizations.
A sample from the DITU dataset provided by ITU (International Telecommunication Union) states that, in 2011, Spain had a value of 23.78 for the TU-B (Broadband subscribers per 100 population) indicator. This information is represented in Turtle as:
| :obs8165 a qb:Observation, wf:Observation ; rdfs:label "ITU B in ESP" ; dct:issued "2013-05-30T09:15:00"^^xsd:dateTime ; cex:indicator :ITU_B ; qb:dataSet :DITU ; cex:value "23.78"^^xsd:float ; cex:ref-area :Spain ; cex:ref-year "2011"^^xsd:gYear ; cex:computation :comp234 . |
Data following the WebIndex data model is richly interrelated. Observations are linked to indicators and to datasets. Datasets contain links to slices. Slices have links both to indicators and back to observations. Both datasets and indicators are linked to the organizations by which they are published or made available. Such links are illustrated in the following example:
| :DITU a qb:DataSet ; qb:structure wf:DSD ; rdfs:label "ITU Dataset" ; dct:publisher :ITU ; qb:slice :ITU09B , :ITU10B, ... :ITU09B a qb:Slice ; qb:sliceStructure wf:sliceByArea ; qb:observation :obs8165, :obs8166, ... :ITU a org:Organization ; rdfs:label "ITU" ; foaf:homepage <http://www.itu.int/> . :Spain wf:iso2 "ES" ; rdfs:label "Spain" . :ITU_B a wf:SecondaryIndicator ; rdfs:label "Broadband subscribers percent"; wf:provider :ITU . |
For verification, the WebIndex data model includes a representation of computations that declare how each observation has been obtained, either from a raw dataset or computed from the observations of other datasets. The structure of computation descriptions, presented in [56], is omitted here for simplicity.
In the next section we formally define the structure of this simplified WebIndex data model using ShEx and review the main differences with the original.
The following declaration indicates that a valid
:Country shape must have exactly one
rdfs:label and exactly one
wf:iso2 both of which must be literals
of type
xsd:string. In the case of
wf:iso2 it must also have length 2.
| :Country { rdfs:label xsd:string ; wf:iso2 xsd:string LENGTH 2 } |
In this example, we deliberately omitted the requirement for a
rdf:type declaration.
This means that, in order to satisfy the
:Country shape,
a node need only have the properties that have been specified and may or may not include
rdf:type declarations.
By default, shape definitions are open
meaning that additional triples with different predicates may be present,
so nodes of shape
:Country could have other properties beyond those
prescribed by the shape.
The shape of datasets is described as follows:
| :DataSet { a [ qb:DataSet ], qb:structure [ wf:DSD ], rdfs:label xsd:string ?, qb:slice @:Slice +, dct:publisher @:Organization } |
This says that nodes conforming to
:DataSet shape must have
rdf:type with value
qb:DataSet,
a
qb:structure of
wf:DSD,
an optional
rdfs:label
of type
xsd:string,
one or more
qb:slice predicates whose object is the subject of a set of triples
matching the
:Slice shape definition and exactly one
dct:publisher,
whose object is the subject of a set of triples matching the
:Organization shape.
The
:Slice shape is defined in a similar fashion:
| :Slice { a [ qb:Slice ], qb:sliceStructure [ wf:sliceByYear ], qb:observation @:Observation+, cex:indicator @:Indicator } |
The
:Observation shape in the WebIndex data model has two
rdf:type declarations, which indicate that
they must be instances of both the RDF Data Cube class of Observation (
qb:Observation) and the
wf:Observation class from the Web Foundation ontology.
The property
dct:publisher is optional, but if it appears, it must have value
wf:WebFoundation.
Values conforming to
:Observation shape can either have a
wf:source property of type
IRI (which, in this context, is used to indicate that it is a raw observation that has been taken from the source represented by the IRI),
or a
cex:computation property whose value conforms to the
:Computation shape.
It should be noted that shapes do not define the semantics of an RDF graph.
While the designers of the WebIndex dataset model have determined that a raw observation would be indicated using the
wf:source predicate and with the object
IRI referencing the original source,
ShEx simply states that, in order for a subject to satisfy the
:Observation, it must include either a
wf:source or a
cex:computation predicate, period.
Meaning must be found elsewhere.
| :Observation { a [ qb:Observation ], a [ wi:Observation ], cex:value xsd:float, dct:issued xsd:dateTime, dct:publisher [wf:WebFoundation]?, qb:dataSet @:DataSet, cex:ref-area @:Country, cex:indicator @:Indicator, cex:ref-year xsd:gYear, ( wf:source IRI | cex:computation @:Computation ) } |
A computation is represented as a node with type
cex:Computation.
| :Computation { a [ cex:Computation ] } |
The type of indicators must be either
wf:PrimaryIndicator or
wf:SecondaryIndicator.
They must also contain the property
wf:provider with a value conforming to shape
:Organization.
| :Indicator { a [ wf:PrimaryIndicator wf:SecondaryIndicator ], wf:provider @:Organization } |
In the case of organizations, we declare these as closed shapes using the
CLOSED modifier and only allow the properties
rdfs:label,
foaf:homepage and
rdf:type, which must have the value
org:Organization.
The
EXTRA modifier is used to declare that we allow other values for the
rdf:type property (using the Turtle keyword
a).
| :Organization CLOSED EXTRA a { a [ org:Organization ], rdfs:label xsd:string, foaf:homepage IRI } |
Shape Expressions offer an intuitive way to describe the contents of linked data portals. They have been used to document both the WebIndex1 and another data portal with a similar model, the Landbook2 data portal. Their documentation defines templates for the different shapes of resources and for the triples that can be retrieved when dereferencing those resources. These templates define the dataset structure in a declarative way and can serve as a contract between developers of the data portal contents and designers of the data model. Having a good data model with a corresponding Shape Expressions specification facilitated the communication between the various stakeholders involved.
The data model described in this chapter differs from the original one for readability and didactic proposes in the following ways:
cex:Computation.
A more detailed description of computations was described at [56].
We have also simplified the representation of the webindex structure,
which was composed of sub-indexes, components and other properties such as labels and provenance information.rdf:type declaration to show that
it is possible to have nodes without that declaration.
In the original WebIndex data model all countries had a mandatory
rdf:type arc but there were several generated nodes
which did not have
rdf:type declarations.
As we omitted the representation of computations we decided to offer that possibility for countries as an example. Appendix A includes the full version of the WebIndex ShEx description used in this book.
Although the original data portal was modeled in ShEx, we undertook the exercise of defining a SHACL description for the same contents so that we could compare the expressiveness of ShEx and SHACL. In this section we present a possible encoding in SHACL.
An equivalent description in SHACL of the
:Country shape defined on
page ?? would be:
| :Country a sh:NodeShape ; sh:property [ sh:path rdfs:label ; sh:datatype xsd:string ; sh:minCount 1; sh:maxCount 1 ; ] ; sh:property [ sh:path wf:iso2 ; sh:datatype xsd:string ; sh:length 2 ; sh:minCount 1; sh:maxCount 1 ; ] . |
As can be seen, the
:Country shape is defined by two constraints which specify that the datatype of
rdfs:label and
wf:iso2 properties must be
xsd:string and that
wf:iso2 has length 2.
The default SHACL cardinality constraint is
[0..*] meaning that cardinality constraints that are omitted in ShEx grammar must be explicitly stated in SHACL as:
| sh:minCount 1; sh:maxCount 1 ; |
Optionality (
? or
* in ShEx) can be represented either by omitting
sh:minCount or by
sh:minCount=0.
An unbounded maximum cardinality (
* or
+ in ShEx) must be represented in SHACL by omitting
sh:maxCount.
As an example, the definition of the
:DataSet shape declares that
rdfs:label is optional (by omitting the
sh:minCount property) and declares that there must be one or more
qb:slice predicates conforming to the
qb:slice definition (by omitting the value of
sh:maxCount).
The predicate
sh:node is used to indicate that the value of a property must have a given shape.
In this way, a shape can refer to another shape.
Note that the WebIndex data model contains cycles—shapes refer to other shapes and those shapes can refer back to the first ones—which can generate recursive shapes.
Nevertheless, the handling of recursion in SHACL is implementation-dependent so it is necessary to circumvent this feature following some of the techniques shown in section 5.12.1).
| :DataSet a sh:NodeShape ; sh:property [ sh:path rdf:type ; sh:hasValue qb:DataSet ; sh:minCount 1; sh:maxCount 1 ; ] ; sh:property [ sh:path qb:structure ; sh:hasValue wf:DSD ; sh:minCount 1; sh:maxCount 1 ; ] ; sh:property [ sh:path rdfs:label ; sh:datatype xsd:string ; sh:maxCount 1 ; ] ; sh:property [ sh:path qb:slice ; sh:node :Slice ; sh:minCount 1 ; ] ; sh:property [ sh:path dct:publisher ; sh:node :Organization ; sh:minCount 1; sh:maxCount 1 ; ] . |
The definition of
:Slice is similar to
:DataSet, so we can omit it for clarity.
The full version of the SHACL shapes that we used in this section is shown in appendix B.
There are three items that need more explanation in the SHACL definition of the
:Observation shape.
The first of these is the repeated appearance of the
rdf:type property with two values.
Although we initially represented it using qualified value shapes, we noticed that it could also be
represented as:
| :Observation a sh:NodeShape ; sh:property [ sh:path rdf:type ; sh:in ( qb:Observation wf:Observation ) sh:property [ sh:path rdf:type ; sh:minCount 2; sh:maxCount 2 ] ; ... |
The definition of observations also contains an optional property with a fixed value. This was defined in ShEx as:
| :Observation { ... dct:publisher (wf:WebFoundation)? ... } |
which means that observations can either have a property
dct:publisher with the fixed
value
wf:WebFoundation or they can not have that property.
A possible representation in SHACL is to use an
sh:or of two shapes:
one in which there is no
dct:publisher (
sh:maxCount=0) and one with exactly one value for
dct:published.
| :Observation ... sh:or ( [ sh:path dct:publisher ; sh:maxCount 0 ] [ sh:path dct:publisher ; sh:hasValue wf:WebFoundation ; sh:minCount 1 ; sh:maxCount 1 ] ) ... |
The last item requiring additional explanation is the disjunction definition which says that observations
must have either the property
cex:computation with a value of shape
:Computation or the property
wf:source with an IRI value, but not both.
In ShEx, it was defined as:
| :Observation { ... , ( cex:computation @:Computation | wf:source IRI ) ... } |
In SHACL, this declaration can be defined using the
sh:xone (exactly one) property constraint:
| :Observation ... sh:xone ( [ sh:path wf:source ; sh:nodeKind sh:IRI ; sh:minCount 1; sh:maxCount 1 ; ] [ sh:path cex:computation ; sh:node :Computation ; sh:minCount 1; sh:maxCount 1 ; ] ) ... |
In the case of indicators we can see again the separation between the
:Indicator shape and
the
wf:PrimaryIndicator and
wf:SecondaryIndicator classes.
| :Indicator a sh:NodeShape ; sh:property [ sh:path rdf:type ; sh:in ( wf:PrimaryIndicator wf:SecondaryIndicator ) ; sh:minCount 1; sh:maxCount 1 ; ] ; ... |
We defined organizations as closed shapes with the possibility that the
rdf:type property has some extra values apart from the
org:Organization.
This constraint can be expressed in SHACL as:
| :Organization a sh:NodeShape ; sh:closed true ; sh:ignoredProperties ( rdf:type ) sh:property [ sh:path rdf:type ; sh:hasValue org:Organization ; ] ; ... |
An important aspect that deserves some explanation is the use of recursion to represent cyclic data models. While ShEx can define cyclic data models in a natural way, the lack of recursion in SHACL needs to be circumvented.
One possibility is to add a discriminating
rdf:type arc to every node so that its shape can be associated to its class.
We opted to add a
sh:targetClass declaration to some shapes, such as
:Observation, conflating that shape
with the class
qb:Observation. Any node that contains a
rdf:type arc pointing to
qb:Observation must conform
to the
:Observation shape declared by the WebIndex.
While this approach may be reasonable in closed contexts, it can cause problems in the open semantic web if one combines data from other datasets.
For example, we defined another data model based on RDF data cube for the LandPortal project3
which also contained values of type
qb:Observation but with different structures.
We consider that forcing every node of type
qb:Observation to have the same structure is not a good practice and that it may be better to separate the target declarations from the shapes definitions.
Fast Healthcase Interoperability Resources (FHIR)4 is a framework created by HL7, a clinical standards organization, to define data formats and APIs for exchanging electronic health records. FHIR Release 3.0 was published in March 2017 and adds support for RDF.
FHIR has a resource-oriented architecture that describes the different entities involved in a clinical record.
In a typical example, a patient (
Patient resource) visits a clinician (
Practitioner resource), who records some observations (
Observation resource), reviews some lab results (
Diagnostic results probably referencing other observations) and diagnoses a clinical issue (
Condition resource).
These resources can be expressed interchangeably in multiple formats:
JSON, XML, and RDF.
FHIR resources are described by structure definitions in a FHIR-specific schema language. This machine-readable language is translated into format-specific schema languages such as XML Schema plus Schematron, JSON Schema, and ShEx.
The structure of FHIR resources is documented as machine-generated HTML tables.
Figure 6.2 shows part of the FHIR
Observation resource5.
FHIR structure definitions have two forms of limited disjunction.
The first, choices of the types of referenced resources, can be seen in
subject and
performer in Figure 6.2.
The second is a choice between a set of datatypes where the name of the datatype is appended to the property name, indicated by the
[x] notation
(see
effective[x] and
value[x] in Figure 6.2).
These are captured in ShEx using the shape expression ShapeOr (’
OR’) and the triple expression OneOf (’
|’) respectively:
| <Observation> CLOSED { a [fhir:Observation]; obs:status @<code> AND {fhir:value @fhirvs:observation-status}; obs:code @<CodeableConcept>; obs:subject ( @<PatientReference> OR @<GroupReference> OR @<DeviceReference> OR @<LocationReference> )?; ( obs:effectiveDateTime @<dateTime> | obs:effectiveTiming @<Timing> )?; obs:issued @<instant>?; obs:performer ( @<PractitionerReference> OR @<OrganizationReference> OR @<PatientReference> OR @<RelatedPersonReference> )*; ( obs:valueQuantity @<Quantity> | obs:valueCodeableConcept @<CodeableConcept> | obs:valueDateTime @<dateTime> | obs:valuePeriod @<Period> )?; obs:bodySite @<CodeableConcept>?; } fhirvs:observation-status ["registered" "preliminary" "final" "amended" ] |

Figure 6.2: Part of Observation resource in FHIR.
The definition of the RDF representation of FHIR was greatly simplified because FHIR was designed to be resource-oriented. While clinical records are not expected to end up on the web, the REST architecture was an easy way to implement addressability and separation of concerns.
This means that FHIR resources are interlinked in a fashion that is already familiar to users of Linked Data.
For example, the
Observation excerpt includes references for the
subject and
performer.
The
subject may be a resource of type
Patient,
Group,
Device or
Location, and the
performer may be a
Practitioner,
Organization,
Patient, or a
RelatedPerson (see Figure 6.2).
While Linked Data is most commonly associated with RDF, these constraints apply equally to the XML and JSON representations of FHIR.
However, of the four schema languages used to validate FHIR, only ShEx validation spans resources.
There are several reasons why one might want to limit validation to a single document: other resources might not be available or relevant and it may be impractical either computationally or procedurally to test conformance of many resources at once. However, a common use case for Linked Data is that all related data is addressable and available. Extending our schema to include verification of external referents allows us to ensure that a resource is coherent not only on its own but also when used in the context of the resources to which it is linked.
The FHIR-specific schemas are expressed as combinations of structure definitions describing types and containership, and constraints.
Most constraints are co-existence constraints, e.g.,
if there is a
duration there must be a
durationUnits.
For XML, structure definitions are expressed as XML Schema, and co-existence constraints are expressed, where possible, in Schematron.
For RDF, structure definitions and coexistence constraints are both expressed in ShEx.
An example with co-existence constraints is the representation of the
Timing datatype, which represents an event that may occur multiple times.
A Timing schedule can be a list of events and/or criteria for when the event happens,
which can be expressed in a structured form and/or as a code. Figure 6.2.2 shows the HTML representation of
Timing.
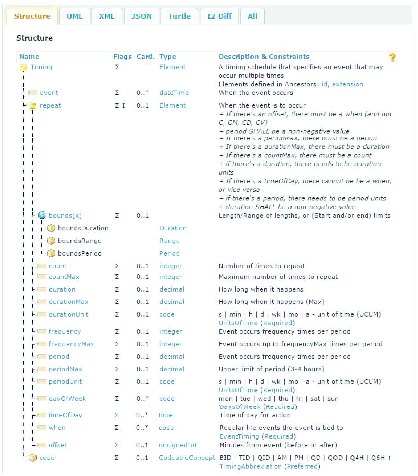
Figure 6.3: Complete Timing datatype in FHIR.
While these human-friendly HTML representations are generated from the FHIR schema, they could easily be generated from representations in other schema languages such as XML Schema, ShEx or SHACL. Schemas using more expressivity may be difficult to convey graphically to users. For instance, these property trees do not have a way to assert co-existence constraints, e.g. that certain properties are mutually exclusive. In a UML stack, these sorts of constraints would be expressed using OCL (see section 3.1.1).
The ShEx representation of
Timing is defined as:
| PREFIX : <http://hl7.org/fhir/Timing.> PREFIX fhirvs: <http://hl7.org/fhir/ValueSet/> BASE <http://hl7.org/fhir/shape/> <Timing> CLOSED { :event @<dateTime>*; :repeat @<Timing.repeat>?; :code @<CodeableConcept>?; } |
where
Timing.repeat shape contains two parts: a structure definition (lines 1–24) and several co-existence constraints (lines 25–35) which can be expressed in natural language as:
duration, there needs to be
durationUnits.
period, there needs to be
periodUnits.
duration shall be a non-negative value.
period shall be a non-negative value.
periodMax, there must be a
period.
durationMax, there must be a
duration.
countMax, there must be a
count.
offset, there must be a
when (and not
C,
CM,
CD,
CV).
timeOfDay, there cannot be a when, or vice versa.
| <Timing.repeat> CLOSED { ( :repeat.boundsDuration @<Duration> | :repeat.boundsRange @<Range> | :repeat.boundsPeriod @<Period> )?; :repeat.count @<integer>?; :repeat.countMax @<integer>?; :repeat.duration @<decimal>?; :repeat.durationMax @<decimal>?; :repeat.durationUnit @<code> AND { fhir:value @fhirvs:units-of-time }?; :repeat.frequency @<integer>?; :repeat.frequencyMax @<integer>?; :repeat.period @<decimal>?; :repeat.periodMax @<decimal>?; :repeat.periodUnit @<code> AND { fhir:value @fhirvs:units-of-time }?; :repeat.dayOfWeek @<code> AND { fhir:value @fhirvs:days-of-week }*; :repeat.timeOfDay @<time>*; :repeat.when @<code> AND { fhir:value @fhirvs:event-timing }*; :repeat.offset @<unsignedInt>?; } AND {(:repeat.duration .; :repeat.durationUnits .)? } AND {(:repeat.period . ; :repeat.periodUnits .)? } AND {:repeat.duration MinInclusive 0 ? } AND {:repeat.period MinInclusive 0 ? } AND {(:repeat.periodMax . ; :repeat.period . )? } AND {(:repeat.durationMax . ; :repeat.duration .)? } AND {(:repeat.countMax . ; :repeat.count .)? } AND { :repeat.offset . ; :repeat.when [. - "C" - "CM" - "CD" - "CV"] | :repeat.when . ? # if there is no offset there can still be a when } AND {:repeat.timeOfDay . | :repeat.when . } |
The value set idiom of specifying a value type and a value set (e.g.,
<code> and
fhirvs:units-of-time) allows one to specify the structure and also to specify values within that structure.
The FHIR/RDF group, a joint undertaking of W3C and HL7, used ShEx not only to define the final product but also to describe intermediate ideas and test them against example data. To this end, members of the group learned ShEx to streamline the process with concrete, testable proposals. During the development and deployment of version 3 of FHIR, Harold Solbrig (Mayo Clinic) implemented a pipeline to test shapes against FHIR example data, catching errors in both the examples and the ShEx schema.
Because the agile FHIR standardization process is centered around the maintenance of FHIR resource structure definitions, the ShEx for FHIR is generated from these definitions. The easy way to do this is to generate ShExJ (the JSON representation) but because the FHIR group wanted these to be appealing to readers, they were transformed into ShExC, making specific white space decisions in the process. These ShExC representations could then be parsed to the abstract syntax to be tested against the reference ShExJ schemas. The latter transformation was simpler and less error prone as it is involved only with the direct semantics.
Because electronic medical records use a consistent template to represent most clinical data, they rely heavily on generic properties.
These properties may be used multiple times with different constraints.
A simple example of this is a blood pressure, which actually consists of two measurements: systolic (pressure during heart beat) and diastolic (pressure between heart beats).
Both of these measurements are connected to the blood pressure measurement by a
fhir:Observation.component
property.
A
<blood-pressure> shape can be defined in ShEx as:
| <blood-pressure> { a [fhir:Observation]; fhir:Observation.component { fhir:Observation.component.code { fhir:CodeableConcept.coding { a [loinc:8480-6] ; # systolic } } ; fhir:Observation.component.valueQuantity { fhir:Quantity.value { fhir:value xsd:decimal }; fhir:Quantity.unit { fhir:value ["mmHg"] }; } } ; fhir:Observation.component { fhir:Observation.component.code { fhir:CodeableConcept.coding { a [loinc:8462-4] ; # diastolic } }; fhir:Observation.component.valueQuantity { fhir:Quantity.value { fhir:value xsd:decimal }; fhir:Quantity.unit { fhir:value ["mmHg"] }; } } } |
and an example data conforming to that shape can be:
| <http://hl7.org/fhir/Observation/blood-pressure> a fhir:Observation; # Passes as a <blood-pressure> fhir:Observation.component [ fhir:Observation.component.code [ fhir:CodeableConcept.coding [ a loinc:8480-6; # systolic ] ]; fhir:Observation.component.valueQuantity [ fhir:Quantity.value [ fhir:value "107"^^xsd:decimal ]; fhir:Quantity.unit [ fhir:value "mmHg" ]; ] ], [ fhir:Observation.component.code [ fhir:CodeableConcept.coding [ a loinc:8462-4; # diastolic ] ]; fhir:Observation.component.valueQuantity [ fhir:Quantity.value [ fhir:value "60"^^xsd:decimal ]; fhir:Quantity.unit [ fhir:value "mmHg" ]; ] ] . |
This example is long, but it is taken directly from a use case.
In fact, its length encourages us to do a bit of factoring.
While we want to keep constraints on the codes for systolic and diastolic, we can create a separate
<valueObs> shape to capture the quantity measurement.
| PREFIX fhir: <http://hl7.org/fhir/> PREFIX loinc: <http://loinc.org/owl#> PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX sct: <http://snomed.info/id/> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> BASE <http://hl7.org/fhir/shape/> <blood-pressure> { a [fhir:Observation]; fhir:Observation.component @<valueObs> AND { fhir:Observation.component.code { fhir:CodeableConcept.coding { a [loinc:8480-6] ; # systolic } } } ; fhir:Observation.component @<valueObs> AND { fhir:Observation.component.code { fhir:CodeableConcept.coding { a [loinc:8462-4] ; # diastolic } } } } <valueObs> { fhir:Observation.component.valueQuantity { fhir:Quantity.value { fhir:value xsd:decimal }; fhir:Quantity.unit { fhir:value ["mmHg"] }; } } |
This schema has two repeated properties:
fhir:Observation.component with different constraints (one for systolic and the other for diastolic). It takes advantage of ShEx’s intuitive additive semantics where requirements for repeated properties
are simply expressed as additional triple patterns (see section 4.6.7).
Springer Nature SciGraph8 is a new Linked Open Data platform aggregating data sources from Springer Nature and key partners from the scholarly domain. The platform currently collates information from across the research landscape, such as funders, research projects, conferences, affiliations, and publications (books and journals). This high-quality data from trusted and reliable sources provides a rich semantic description of how information is related, as well as enabling innovative visualizations of the scholarly domain.
Data quality is a key component in SciGraph. In earlier work, SPIN was used in various validation scenarios. However, SPIN was hard to maintain and to read by non-experts and SHACL was chosen instead. SHACL is now used to validate data before the data enters the main triplestore. SHACL is also used to specify which classes and properties can be published from the triplestore.
All of the SHACL shapes used in building public datasets of Springer Nature SciGraph are published in a Github repository.9 There are shapes that define the RDF structure of all SciGraph entity types such as articles, grants, and journals.
The following snippet of the
Article shape says that all SHACL instances of
sg:Article must have
exactly one
sg:scigraphId that is a string,
at most one value for
sg:doi,
a string following a specific pattern and at most one value for
sg:role that can be one of:author, editor or principal investigator.
| :Article a sh:NodeShape ; sh:targetClass sg:Article ; rdfs:label "RDF shape for the sg:Article model" ; # Identity sh:property [ sh:path sg:scigraphId ; sh:datatype xsd:string ; sh:minCount 1 ; sh:maxCount 1 ; ] ; sh:property [ sh:path sg:doi ; sh:datatype xsd:string ; sh:pattern "^10\\.\\d{4,5}\\/\\S+$" ; sh:maxCount 1 ; ] ; # ... sh:property [ sh:path sg:role ; sh:in ( "author" "editor" "principal investigator" ) ; sh:maxCount 1 ; ] ; |
DBpedia10 ([60]) is a crowdsourced community effort to extract structured information from Wikipedia and make this information available on the Web. DBpedia data is available as RDF dumps, through a linked data interface and a SPARQL endpoint. The current DBpedia release (version 2016-0411) provides circa 9.5 billion RDF triples.
Validating such large amounts of RDF data is a challenging task, and various methods have been applied. At the time of writing, the core validation of DBpedia is performed with neither ShEx nor SHACL. However, it is worth mentioning some approaches that work on large and noisy datasets.
One of the core sources of validation for DBpedia is the DBpedia ontology. The DBpedia ontology is crowdsourced and maintained by the community on the http://mappings.dbpedia.org wiki. At the time of writing, the ontology consists of circa 750 classes, organized in a hierarchy, and 2,600 properties. The community can define class disjoint statements and for properties, axioms such as domain, range, literal datatypes, and functional properties. The DBpedia ontology both drives the correct extraction of RDF triples from Wikipedia pages and is used in post-processing steps to remove data violations.
The DBpedia extraction framework has many extractors that parse different parts of a Wikipedia page and generate RDF triples.
The Mapping-based extractor is a special extractor that focuses on high-quality extraction from Wikipedia infoboxes.
To achieve this it uses the DBpedia ontology and the community-maintained infobox-to-ontology mappings.
Each infobox mapping maps a Wikipedia infobox template to a DBpedia class and each infobox template parameter to a property mapping (see [60, sec. 2.4]) .
At extraction time, each property mapping is associated with a different parser, according to the
rdfs:range of the DBpedia property of each property mapping.
For example, if the range of a property is defined as an
xsd:date (e.g.
dbo:birthDate), property mappings with this property generate a value only if the value can be parsed as a date.
As a post-processing step, the RDFS and OWL axioms defined in the DBpedia ontology are used to further clean up the extracted data.
A common approach is to run RDFUnit on the data and get back detailed violation reports.
These reports are used to identify common sources of error that can be planned for fixing.
Another approach is a set of scripts that parse facts and, depending on the conformance of a fact to a set of axioms (e.g.,
rdfs:domain,
rdfs:range,
owl:disjointWith, etc)
dispatches the facts to different dataset buckets before publishing.
A very common way to generate RDF data is through a mapping document. In a general case, a mapping document contains rules that can be used to transform input data to RDF. The mapping rules can be encoded in a script (e.g., using XSLT), in code, or formulated in mapping languages such as R2RML [28] and RML [30].
A single error in the mapping document can, in many cases, be propagated to many errors on the generated instance data,
and the number of errors is usually proportional to the input size.
Consider for example a mapping document that generates person data and represents the age of a person with the property
foaf:age and the value as
xsd:double instead of
xsd:integer.
Every person instance in the generated RDF will have a violation for the datatype of
foaf:age.
Fixing such errors in the mapping document is an easy task, but
once the data is generated the task becomes harder, especially on big datasets.
Dimou et al. [31] propose a workflow for including quality assessment of the mappings in the general dataset quality assessment workflow. The authors use the dataset schema information (i.e., ontologies) to identify schema errors of the dataset directly from an RML mapping document. The results illustrate that violations such as domain and range, mistyped datatypes, class and property disjointness, and the like can be identified directly from the mapping document. Evaluation of this work indicates that fixing errors directly in the mapping document is more efficient. For example, in the case of DBpedia, an automatic quality assessment of the mappings took less than a minute while the complete dataset validation took more than 16 hours.
However, the mapping quality assessment of the mappings cannot identify all possible schema errors in the target dataset. Some constraints, such as cardinality, can only be identified on the target dataset.
Even though this approach currently works with OWL and RDFS, it would be an easy exercise to extend it to SHACL or ShEx. Given a set of mappings and a set of Shapes, one could identify incompatibilities directly from the mapping document.
DBpedia promotes Github for accepting link contributions from the DBpedia community12 and, recently, there has been an effort to automate the link verification process (see [32, Section 3.3]). This has put into place a set of quality checks that validate various aspects of the link submission and is integrated with common continuous integration services, such as Travis CI.
This approach enables instant checks on pull requests and reports problems to the submitter. In addition to scripts that check for instance valid RDF files, there is a script that checks if the link manifest file conforms to the following SHACL schema.13
| dbp:LinkManifest a sh:NodeShape ; sh:targetClass void:Linkset ; sh:property [ sh:path dc:author ; sh:minCount 1; sh:nodeKind sh:IRI ; ] ; sh:property [ sh:path dct:description ; sh:minCount 1; sh:nodeKind sh:Literal ; sh:datatype xsd:string ; ] ; sh:property [ sh:path dct:license ; sh:minCount 1; sh:nodeKind sh:IRI ; ] ; sh:property [ sh:path dbp:script ; sh:maxCount 1; sh:nodeKind sh:IRI ; ] ; sh:property [ sh:path dbp:linkConf ; sh:maxCount 1; sh:nodeKind sh:IRI ; ] ; sh:property [ sh:path dbp:ntriplefilelocation ; sh:maxCount 1; sh:nodeKind sh:IRI ; ] ; sh:property [ sh:path dbp:endpoint ; sh:maxCount 1; sh:nodeKind sh:IRI ; ] ; sh:property [ sh:path dbp:constructQuery ; sh:maxCount 1; sh:nodeKind sh:Literal ; sh:datatype xsd:string ; ] ; sh:property [ sh:path dbp:approvedPatch ; sh:nodeKind sh:IRI ; ] ; sh:property [ sh:path dbp:optionalPatch ; sh:nodeKind sh:IRI ; ] ; sh:property [ sh:path dbp:updateFrequencyInDays ; sh:maxCount 1; sh:nodeKind sh:Literal ; sh:datatype xsd:integer ; ] ; |
The defined quality checks cannot capture all possible errors in a link submission process. However, they can (a) provide a very useful feedback to the link submitter, and (b) enable DBpedia to automatically pre-process some steps in the link generation pipeline.
The DBpedia ontology has been maintained by the DBpedia community in a crowdsourced manner at the http://mappings.dbpedia.org wiki. There is an ongoing effort to move ontology development onto Github for easier collaboration and for the sake of more control over the ontology structure. 14 At the time of writing, the following constraints are defined to ensure that each DBpedia class and each DBpedia property conform to DBpedia community requirements:
rdfs:label and at least one
rdfs:comment that are of
rdf:langString datatype with unique language.
rdfs:domain.
rdfs:range.
owl:Class.
These constraints are implemented with the following SHACL definitions. RDFUnit is used to perform the validation as well as integrate with Travis CI and automate the checks on each commit and pull request.
| dbo-shape:ClassShape a sh:Shape ; sh:targetClass owl:Class ; sh:targetSubjectsOf rdfs:subClassOf ; sh:severity sh:Error ; sh:property [ sh:message "Each owl:Class should have at least one rdfs:label" ; sh:path rdfs:label ; sh:minCount 1; sh:dataType rdf:langString; sh:uniqueLang true ; ] ; sh:property [ sh:message "Each owl:Class should have at least one rdfs:comment" ; sh:path rdfs:comment ; sh:minCount 1; sh:dataType rdf:langString; sh:uniqueLang true ; ] ; sh:property [ sh:message "Each owl:Class should have at most one superclass" ; sh:path rdfs:subClassOf ; sh:maxCount 1; ] ; sh:sparql [ sh:message "DBpedia Ontology only allows 9 top level classes, any new top level classes need to be discussed" ; sh:severity sh:Warning ; sh:select """ PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT DISTINCT $this ?otherClass WHERE { $this rdfs:subClassOf owl:Thing . FILTER($this NOT IN ( <http://dbpedia.org/ontology/Activity>, <http://dbpedia.org/ontology/Agent>, <http://dbpedia.org/ontology/Concept>, <http://dbpedia.org/ontology/CommunicationSystem>, <http://dbpedia.org/ontology/Condition>, <http://dbpedia.org/ontology/Event>, <http://dbpedia.org/ontology/PhysicalThing>, <http://dbpedia.org/ontology/Place>, <http://dbpedia.org/ontology/TimePeriod>) ). } """ ; ] . dbo-shape:PropertyShape a sh:Shape ; sh:targetClass rdf:Property ; sh:targetClass owl:DatatypeProperty ; sh:targetClass owl:ObjectProperty ; sh:targetSubjectsOf rdfs:subPropertyOf ; sh:property [ sh:message "Each property should have at least one rdfs:label" ; sh:path rdfs:label ; sh:minCount 1; sh:dataType rdf:langString; sh:uniqueLang true ; ] ; sh:property [ sh:message "Each property should have at least one rdfs:comment" ; sh:path rdfs:comment ; sh:minCount 1; sh:dataType rdf:langString; sh:uniqueLang true ; ] ; sh:property [ sh:message "Each property should have at most one rdfs:domain" ; sh:path rdfs:domain ; sh:maxCount 1; ] ; sh:property [ sh:message "Each property should have an rdfs:domain that is defined as an owl:Class" ; sh:path rdfs:domain ; sh:class owl:Class; ] ; sh:property [ sh:message "Each property should have at most one rdfs:range" ; sh:path rdfs:range ; sh:maxCount 1; ] ; sh:property [ sh:message "Each property should have an rdfs:range that is defined as an owl:Class" ; sh:path rdfs:range ; sh:class owl:Class; ] ; sh:property [ sh:message "Each property should have at most one super property" ; sh:path rdfs:subPropertyOf ; sh:maxCount 1; ] . |
An interesting part of this use case is the use of SHACL-SPARQL to define the complex constraint Top-level DBpedia classes must be discussed before defined.
Here, only nine specific classes are allowed as top-level classes (i.e. classes with no superclass except
owl:Thing) and are hard-coded in the SPARQL query.
Even though this creates a tight coupling of the shape to the data, top-level DBpedia classes are not changing frequently and adjusting the constraint can indeed stimulate discussion.
Given that one serialization format for ShEx is RDF, it is possible to use ShEx to validate itself, i.e., to validate RDF graphs representing ShEx schemas. The RDF serialization representation of ShEx is called ShExR.
The following example contains a simple ShEx schema using ShExR in Turtle:
| <> a sx:Schema ; sx:shapes :User . :User a sx:Shape; sx:expression [ a sx:EachOf ; sx:expressions ( [ a sx:TripleConstraint ; sx:predicate schema:name ; sx:valueExpr [ a sx:NodeConstraint ; sx:datatype xsd:string ] ] [ a sx:TripleConstraint ; sx:predicate schema:gender ; sx:valueExpr [ a sx:NodeConstraint ; sx:values ( schema:Male schema:Female ) ] ] ) ] . |
In the following, we will describe the ShEx schemas that can validate RDF files in ShExR (as above). The full code is included in the annex C and has been adapted from Appendix C (ShEx shape) of the ShEx specification.15
ShExR graphs contain an RDF node with
rdf:type sx:Schema,
an optional list of starting semantic actions,
a start declaration and zero or more
sx:shapes declarations whose values
must be shape expressions
<ShapeExpr>.
Most of the shapes in this schema are defined as
CLOSED to limit the appearance of unexpected triples.
| <Schema> CLOSED { a [sx:Schema] ; sx:startActs @<SemActList1Plus>? ; sx:start @<ShapeExpr>?; sx:shapes @<ShapeExpr>* } |
As discussed in Section 4.4.3, there are six possibilities for defining shape expressions. Which can be enumerated as:
| <ShapeExpr> @<ShapeOr> OR @<ShapeAnd> OR @<ShapeNot> OR @<NodeConstraint> OR @<Shape> OR @<ShapeExternal> |
<ShapeOr> and
<ShapeAnd> have a similar representation which contains a list of at least two shape expressions
represented by the
<shapeExprList2Plus> shape, which will be described later.
| <ShapeOr> CLOSED { a [sx:ShapeOr] ; sx:shapeExprs @<shapeExprList2Plus> } <ShapeAnd> CLOSED { a [sx:ShapeAnd] ; sx:shapeExprs @<shapeExprList2Plus> } |
<ShapeNot> contains a shape expression:
| <ShapeNot> CLOSED { a [sx:ShapeNot] ; sx:shapeExpr @<shapeExpr> } |
The following code represents lists of shape expressions.
<shapeExprList2Plus is a list of at least two shape expressions, and
<shapeExprList1Plus> is a list of at least one.
| <shapeExprList2Plus> CLOSED { rdf:first @<shapeExpr> ; rdf:rest @<shapeExprList1Plus> } <shapeExprList1Plus> CLOSED { rdf:first @<shapeExpr> ; rdf:rest [rdf:nil] OR @<shapeExprList1Plus> } |
Node constraints are formed by one or more declarations of node kind, datatype, string facet, numeric facet, or a list of possible values.
| <NodeConstraint> CLOSED { a [sx:NodeConstraint] ; ( sx:nodeKind [sx:iri sx:bnode sx:literal sx:nonliteral] | sx:datatype IRI | &<stringFacet> | &<numericFacet> | sx:values @<valueSetValueList1Plus> )+ } |
A shape can contain the Boolean directives
sx:closed and
sx:extra as well as a
sx:tripleExpression and an optional list of semantic actions.
| <Shape> CLOSED { a [sx:Shape] ; sx:closed [true false]? ; sx:extra IRI* ; sx:expression @<tripleExpression>? ; sx:semActs @<SemActList1Plus>? ; } |
External shapes only contain a type declaration.
| <ShapeExternal> CLOSED { a [sx:ShapeExternal] ; } |
Semantic actions contain a
sx:name that points to an IRI describing the processor and a
sx:code value with the string code that will be passed to that processor.
| <SemAct> CLOSED { a [sx:SemAct] ; sx:name IRI ; sx:code xsd:string? } |
Annotations contain a predicate (which must be an IRI) and an object.
| <Annotation> CLOSED { a [sx:Annotation] ; sx:predicate IRI ; sx:object @<objectValue> } |
String and numeric facets just enumerate the different possibilities:
| <stringFacet> { sx:length xsd:integer | sx:minlength xsd:integer | sx:maxlength xsd:integer | sx:pattern xsd:string } <numericFacet> { sx:mininclusive @<numericLiteral> | sx:minexclusive @<numericLiteral> | sx:maxinclusive @<numericLiteral> | sx:maxexclusive @<numericLiteral> | sx:totaldigits xsd:integer | sx:fractiondigits xsd:integer } <numericLiteral> xsd:integer OR xsd:decimal OR xsd:double |
The values that can appear in a value set are object values, stems, or ranges:
| <valueSetValue> @<objectValue> OR @<IriStem> OR @<IriStemRange> OR @<LiteralStem> OR @<LiteralStemRange> OR @<LanguageStem> OR @<LanguageStemRange> |
Object values can be IRIs or literals:
| <objectValue> IRI OR LITERAL |
Stems and ranges are defined for the different possibilities: IRIs, literals, or language-tagged literals.
| <IriStem> CLOSED { a [sx:IriStem]; sx:stem xsd:anyUri } <IriStemRange> CLOSED { a [sx:IriStemRange]; sx:stem xsd:anyUri OR @<Wildcard>; sx:exclusion @<objectValue> OR @<IriStem>* } <LiteralStem> CLOSED { a [sx:LiteralStem]; sx:stem xsd:string } <LiteralStemRange> CLOSED { a [sx:LiteralStemRange]; sx:stem xsd:string OR @<Wildcard>; sx:exclusion @<objectValue> OR @<LiteralStem>* } <LanguageStem> CLOSED { a [sx:LanguageStem]; sx:stem xsd:string } <LanguageStemRange> CLOSED { a [sx:LanguageStemRange]; sx:stem xsd:string OR @<Wildcard>; sx:exclusion @<objectValue> OR @<LanguageStem>* } <Wildcard> BNODE CLOSED { a [sx:Wildcard] } |
A triple expression is either a triple constraint, an inclusion of another shape expression of a composed triple expression made from
<OneOf> or
<EachOf>.
| <tripleExpression> @<TripleConstraint> OR @<OneOf> OR @<EachOf> OR @<Inclusion> |
The definition of
<OneOf> and
<EachOf> is very similar:
they contain
sx:min and
sx:max cardinalities.
a list of at least two triple expressions,
and optional list of semantic actions and a list of annotations.
| <OneOf> CLOSED { a [sx:OneOf] ; sx:min xsd:integer? ; sx:max xsd:integer? ; sx:expressions @<tripleExpressionList2Plus> ; sx:semActs @<SemActList1Plus>? ; sx:annotation @<Annotation>* } <EachOf> CLOSED { a [sx:EachOf] ; sx:min xsd:integer? ; sx:max xsd:integer? ; sx:expressions @<tripleExpressionList2Plus> ; sx:semActs @<SemActList1Plus>? ; sx:annotation @<Annotation>* } |
<tripleExpressionList2Plus> declares a list of at least two triple expressions.
| <tripleExpressionList2Plus> CLOSED { rdf:first @<tripleExpression> ; rdf:rest @<tripleExpressionList1Plus> } <tripleExpressionList1Plus> CLOSED { rdf:first @<tripleExpression> ; rdf:rest [rdf:nil] OR @<tripleExpressionList1Plus> } |
A
<tripleConstraint> contains a mandatory
sx:predicate property, an optional value expression, the cardinality declarations
sx:min and
sx:max, the
sx:inverse and
sx:negated qualifiers and the semantic actions and annotations.
| <TripleConstraint> CLOSED { a [sx:TripleConstraint] ; sx:inverse [true false]? ; sx:negated [true false]? ; sx:min xsd:integer? ; sx:max xsd:integer? ; sx:predicate IRI ; sx:valueExpr @<shapeExpr>? ; sx:semActs @<SemActList1Plus>? ; sx:annotation @<Annotation>* } |
An inclusion has a predicate
sx:include that points to an IRI or a blank node (non-literals).
| <Inclusion> CLOSED { a [sx:Inclusion]? ; sx:include NONLITERAL } |
The following definitions declare lists of at least one element: semantic actions or value set values.
| <SemActList1Plus> CLOSED { rdf:first @<SemAct> ; rdf:rest [rdf:nil] OR @<SemActList1Plus> } <valueSetValueList1Plus> CLOSED { rdf:first @<valueSetValue> ; rdf:rest [rdf:nil] OR @<valueSetValueList1Plus> } |
In this section we describe how to use SHACL to validate Shapes graphs that contain SHACL code. This is similar to what we described in the previous section although in this case we are using SHACL to validate SHACL. The full code described in this section appears in Appendix D and has been adapted from Appendix C of the SHACL specification. We have done some modifications to the original code for readability.
The document declares the shape of shapes
:ShapeShape as a
sh:NodeShape that contains a long list of target declarations to define the nodes that must be validated as shapes.
| sh:targetClass sh:NodeShape, sh:PropertyShape ; sh:targetSubjectsOf sh:targetClass, sh:targetNode, sh:targetObjectsOf, sh:targetSubjectsOf , sh:and, sh:class, sh:closed, sh:datatype, sh:disjoint, sh:equals, sh:flags, sh:hasValue, ... # All the other constraint component parameters sh:targetObjectsOf sh:node, sh:not, sh:property sh:qualifiedValueShape . |
It declares that every node that is an instance of
sh:NodeShape or
sh:PropertyShape
must conform to
:ShapeShape
and that the subjects of properties
sh:targetClass,
sh:targetNode, …must also conform to
:ShapeShape
as well as the objects of
sh:node,
sh:not,
sh:property,
and
sh:qualifiedValueShape.
The next statement declares that nodes conforming to shapes,
must conform to one of
:NodeShapeShape or
:PropertyShapeShape.
| :ShapeShape sh:xone ( :NodeShapeShape :PropertyShapeShape ) ; |
The following statements declare the types of values that can be associated with target declarations.
| :ShapeShape sh:property [ sh:path sh:targetNode ; sh:nodeKind sh:IRIOrLiteral ; ] ; sh:property [ sh:path sh:targetClass ; sh:nodeKind sh:IRI ; ] ; sh:property [ sh:path sh:targetSubjectsOf ; sh:nodeKind sh:IRI ; ] ; sh:property [ sh:path sh:targetObjectsOf ; sh:nodeKind sh:IRI ; ] ; ... |
In the same way, it declares the values that can have the different constraint components.
| :ShapeShape sh:property [ sh:path sh:severity ; sh:maxCount 1 ; sh:nodeKind sh:IRI ; ] ; sh:property [ sh:path sh:deactivated ; sh:maxCount 1 ; sh:in ( true false ) ; ] ; sh:property [ sh:path sh:and ; sh:node :ListShape ; ] ; sh:property [ sh:path sh:class ; sh:nodeKind sh:IRI ; ] ; ... |
We omit the full list of declarations as all of them follow the same style.
They declare the expected value of each predicate. For example, in the last case,
that the predicate
sh:class can have an IRI as value.
A remarkable aspect is the following declaration:
| :ShapeShape sh:or ( [ sh:not [ sh:class rdfs:Class ; sh:or ( [ sh:class sh:NodeShape ] [ sh:class sh:PropertyShape ] ) ] ] [ sh:nodeKind sh:IRI ] ). |
It represents a syntax rule of implicit class targets
(see Section 5.7.3) by which a NodeShape or PropertyShape that are also instances of
rdfs:Class must be IRIs.
This is an example of an
IF-THEN pattern (see Section 5.11.5) and could be defined in pseudo-code as:
| IF (sh:class rdfs:Class AND (sh:class sh:NodeShape OR sh:class sh:PropertyShape) ) THEN sh:nodeKind sh:IRI |
Another interesting declaration is:
| sh:path sh:message ; sh:or ( [ sh:datatype xsd:string ] [ sh:datatype rdf:langString ] ) ; ] . |
which declares that messages can be any string literal or languages tagged string literal, which is a common pattern for messages that admit not only plain string literals but multilingual ones.
Another aspect that can be remarked is the use of
:ListShape as the value of several predicates like
sh:and,
sh:or,
sh:in,
sh:ignoredProperties, and
sh:xone.
The declarations are done as:
| sh:path sh:and ; sh:node :ListShape ; ] ; sh:property [ sh:path sh:or ; sh:node :ListShape ; ] ; # ... similar for the other predicates . |
The meaning is that the values of those predicates must be well-formed RDF lists (see Section 2.2).
An RDF list is a collection of values linked by the
rdf:rest predicate whose last value is
rdf:nil.
Each node in the list must contain exactly one value of
rdf:first.
The declaration of
:ListShape is defined as:
| sh:property [ sh:path [ sh:zeroOrMorePath rdf:rest ] ; sh:hasValue rdf:nil ; sh:node :ListNodeShape ; ] . |
which means that all the nodes are linked by the predicate
rdf:rest zero or more times, and that those nodes must conform to
:ListNodeShape which is defined as:
| sh:or ( [ sh:hasValue rdf:nil ; sh:property [ sh:path rdf:first ; sh:maxCount 0 ] ; sh:property [ sh:path rdf:rest ; sh:maxCount 0 ] ; ] [ sh:not [ sh:hasValue rdf:nil ] ; sh:property [ sh:path rdf:first ; sh:maxCount 1 ; sh:minCount 1 ] ; sh:property [ sh:path rdf:rest ; sh:maxCount 1 ; sh:minCount 1 ] ; ]) . |
This means that a list node is either
rdf:nil, in which case it must not have any arc with predicates
rdf:first or
rdf:rest, or
a node with exactly one value for those predicates.
In this case, the pattern followed is an
IF-THEN-ELSE pattern.
In the case of
sh:ignoredProperties and
sh:languageIn,
the list nodes must also conform to some specific shape (to be an IRI or a string). This can be expressed as:
| sh:path (sh:ignoredProperties [sh:zeroOrMorePath rdf:rest] rdf:first); sh:nodeKind sh:IRI ; ]; sh:property [ sh:path (sh:languageIn [sh:zeroOrMorePath rdf:rest] rdf:first) ; sh:datatype xsd:string ; ] . |
Similarly, a constraint is established on the values of
sh:and,
sh:or and
sh:xone which must be lists of nodes conforming to
:ShapeShape. This is declared as:
| :ShapesListShape a sh:NodeShape ; sh:property [ sh:path ( [ sh:zeroOrMorePath rdf:rest ] rdf:first ) ; sh:node :ShapeShape ; ] . |
Some properties, like the
sh:path,
sh:lessThan,
sh:minCount, etc. cannot be applied to node shapes.
This constraint is declared as:
| :NodeShapeShape a sh:NodeShape ; sh:property [ sh:path sh:path ; sh:maxCount 0 ] ; sh:property [ sh:path sh:lessThan ; sh:maxCount 0 ] ; sh:property [ sh:path sh:maxCount; sh:maxCount 0 ]; ... # Similar for sh:lessThanOrEquals, sh:minCount, # sh:qualifiedValueShape and sh:uniqueLang |
Property shapes must have exactly one value for property
sh:path.
| :PropertyShapeShape a sh:NodeShape ; sh:property [ sh:path sh:path ; sh:maxCount 1 ; sh:minCount 1 ; sh:node :PathShape ] . |
The value of
sh:path must conform to
:PathShape.
The first version of
:PathShape employed recursion with the following pattern:
| :PathShape a sh:NodeShape ; sh:xone ( [ sh:nodeKind sh:IRI ] [ sh:nodeKind sh:BlankNode ; sh:node :PathListWithAtLeast2Members ; ] [ sh:nodeKind sh:BlankNode ; sh:closed true ; sh:property [ sh:path sh:alternativePath ; sh:node :PathListWithAtLeast2Members ; sh:minCount 1 ; sh:maxCount 1 ; ] ] [ sh:nodeKind sh:BlankNode ; sh:closed true ; sh:property [ sh:path sh:inversePath ; sh:node :PathShape ; # Recursive reference sh:minCount 1 ; sh:maxCount 1 ; ] ] ...# similar for sh:zeroOrMorePath, sh:oneOrMorePath # and sh:zeroOrOnePath ); . |
However, as recursion is undefined in SHACL, that definition was changed to simulate recursion using the property path
sh:zeroOrMorePath with an auxiliary shape
(see Section 5.12.1).
The new definition is:
| :PathShape a sh:NodeShape ; sh:property [ sh:path [ sh:zeroOrMorePath _:PathPath ] ; sh:node :PathNodeShape ; ] . _:PathPath sh:alternativePath ( ( [ sh:zeroOrMorePath rdf:rest ] rdf:first ) ( sh:alternativePath [ sh:zeroOrMorePath rdf:rest ] rdf:first ) sh:inversePath sh:zeroOrMorePath sh:oneOrMorePath sh:zeroOrOnePath ) . :PathNodeShape sh:xone ( [ sh:nodeKind sh:IRI ] [ sh:nodeKind sh:BlankNode ; sh:node :PathListWithAtLeast2Members ; ] [ sh:nodeKind sh:BlankNode ; sh:closed true ; sh:property [ sh:path sh:alternativePath ; sh:node :PathListWithAtLeast2Members ; sh:minCount 1 ; sh:maxCount 1 ; ] ] [ sh:nodeKind sh:BlankNode ; sh:closed true ; sh:property [ sh:path sh:inversePath ; sh:minCount 1 ; sh:maxCount 1 ; ] ] ...# similar for sh:zeroOrMorePath, sh:oneOrMorePath # and sh:zeroOrOnePath ) . |
The previous definitions use the following auxiliary shape
:PathListWithAtLeast2Members:
| :PathListWithAtLeast2Members a sh:NodeShape ; sh:node :ListShape ; sh:property [ sh:path [ sh:oneOrMorePath rdf:rest ] ; sh:minCount 2 ; # 1 other list node plus rdf:nil ] . |
The last two definitions declare that the values of
sh:shapesGraph and the values of
sh:entailment must be IRIs.
| :ShapesGraphShape a sh:NodeShape ; sh:targetObjectsOf sh:shapesGraph ; sh:nodeKind sh:IRI . :EntailmentShape a sh:NodeShape ; sh:targetObjectsOf sh:entailment ; sh:nodeKind sh:IRI . |
Observation resource is at http://hl7.org/fhir/observation.html